While looking for something else this week I found my old posts on the Carlisle method (2017) and the one year later follow up (2018). Seemed time for yet another update, so here we are.
For those of you without a photographic memory for random data controversies from 9 years ago, the Carlisle method was a statistical method by research John Carlisle who was attempting to figure out a way to identify potentially fraudulent papers more quickly than undertaking laborious investigations. His idea was to actually look at the baseline data for control groups and intervention groups and to try to detect data anomalies there, assuming that authors would have focused much more on their results than on their baseline data so anomalies would be easier to spot. He named a bunch of studies that appears to have skewed baseline data, and others took it from there.
Interestingly, while some studies did end up having to adjust, it did become clear this method was not always detecting fraud. In a few cases some of the statistics were actually just mislabeled. In the most notable case, it turned out the study authors had not been clear on how their samples were selected, and they had to update their results without some of their original data.
So what’s happened since then? Well in 2021 Carlisle decided to use his prior method and standing as a journal editor to take things up a notch. While his initial method was a quick screening, he decided to develop a screening tool to flag papers that might have a problem. This included “previous false data from one or more authors or the research institute; inconsistencies in registered protocols; content copied from published papers, including tables, figures and text; unusually dissimilar or unusually similar mean (SD) values for baseline variables; or incredible results”. If a paper flagged as having these risk factors, he would ask for a spreadsheet with the patient level data in it so he could look at it more closely to ensure it was ok.
Unsurprisingly, he found problems. But what happened next was even worse.
Carlisle discovered that when he followed up with the universities these papers were coming from, he discovered that the universities these authors were from actually were not overly anxious to investigate the particular concerns he was raising, which concerned even more. So starting in 2019, Carlisle decided the journal would ask for patient level data from everyone from the countries that submitted the most papers: Egypt, China, India, Iran, Japan, South Korea, and Turkey. The results were not encouraging:
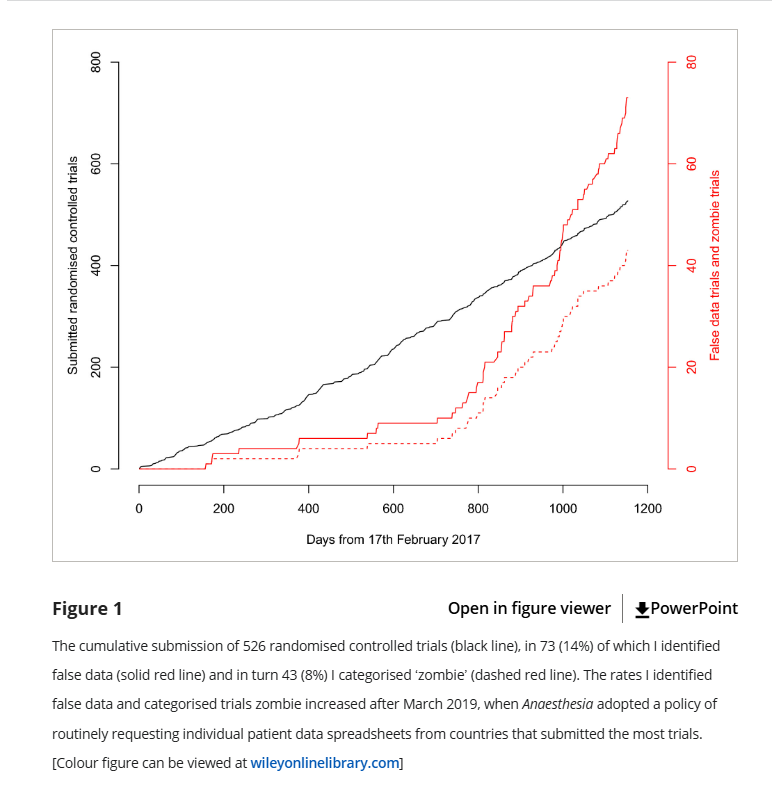
Basically, when Carlisle screened for high risk papers, he found about 10 “false” papers in 2 years. When he screened everyone, he found 60+ papers in the next 2 years. Yikes. Just to clarify what he means by “false” or “zombie”, here it is in his words:
Data I categorised as false included: the duplication of figures, tables and other data from published work; the duplication of data in the rows and columns of spreadsheets; impossible values; and incorrect calculations. I have chosen the word ‘zombie’ to indicate trials where false data were sufficient that I think the trial would have been retracted had the flaws been discovered after publication. The varied reasons for declaring data as false precluded a single threshold for declaring the falsification sufficient to deserve the name ‘zombie’, although I have explicitly stated my reasoning for each trial in the online Supporting Information (Appendix S1).
So overall 14% of papers submitted had substantial flaws and 8% were retraction worthy, but that rate went way up after they started requesting data from everyone. Unfortunately Carlisle ended by mentioning a few fairly discouraging things:
- He has no reason to believe his journal was attracting particularly bad papers. One might actually assume the opposite given that he very publicly was out fighting fraud for several years before this.
- It took him a really long time to look through the spreadsheets, and sometimes he only caught the fake data on the 2nd, 3rd or 4th look.
- Fraud can actually happen at any level of research, which makes it scary. It one case he mentions, the researchers discovered it was a med student they were working with who made up the data. We think of scientific fraud as the big name getting the credit, but you can see where it’s actually really likely it’s an overwhelmed lower level person trying to deliver results to them who might actually provide fake data.
- Nothing stops people from submitting these papers to other journals that don’t have this level of scrutiny.
In the end Carlisle concludes that these types of data errors or fraud are so common that developing screening tools for them should be a primary goal of journals, lest they risk up to a quarter of their studies being retraction worthy. Not great, but thank God for people like Carlisle.
