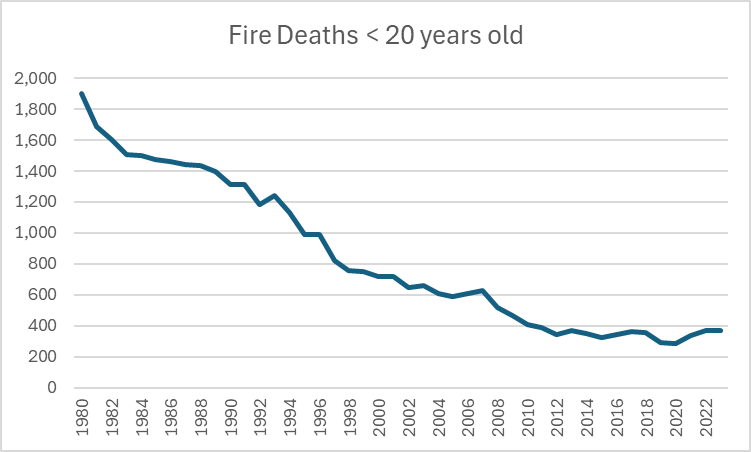
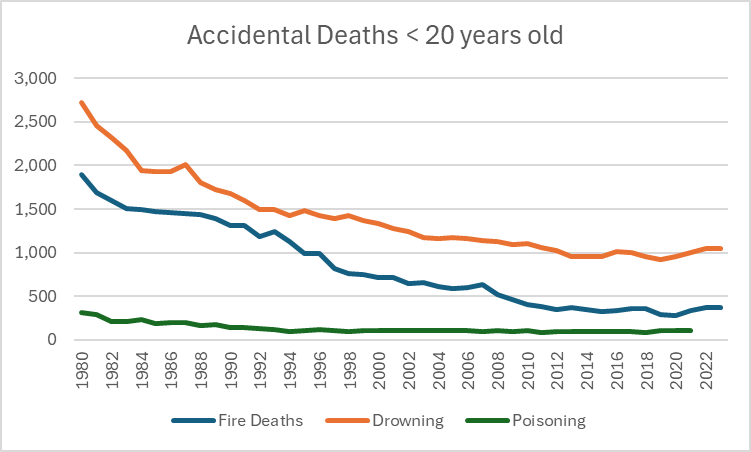
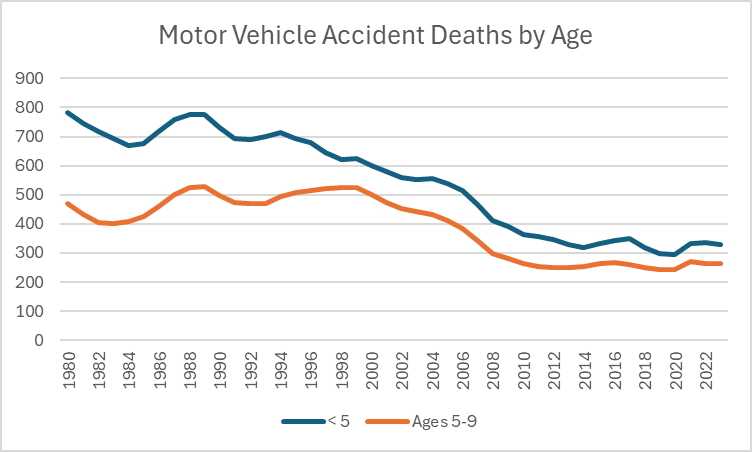
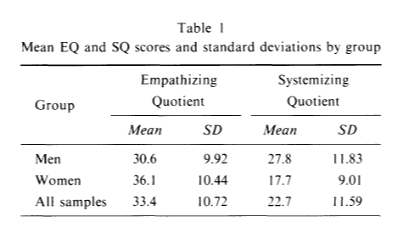
A new poll on police attitudes and the Karen Read case reminds us of some interesting things about how the public answers surveys. Crossposted from Exhibit Asterisk.
One of the more fun things I’ve done over the course of my career is spend some time designing and sending out survey questions. Survey methodology is a whole subfield, and you find out quickly that there’s a lot that goes in to how you ask a question.
I was thinking about this a few days ago when headlines started popping up about a case from my area: “Most in Mass think police hid evidence in the Karen Read case”. The headline was based off of the Bay State Poll, a States of Opinion Project , conducted by the University of New Hampshire Survey Center that surveyed about 7001 Massachusetts residents and ran the results under their headline “Most Bay Staters Believe Police Concealed Evidence in Read Case and Police Conduct is Evidence of a Wider Problem”.
For those of you not from around here, the Karen Read case has been capturing headlines around here for over 4.5 years now. It involves a woman accused of killing her police officer boyfriend in a drunk driving accident back in January 2022, while she claims she was framed by police and those who testified against her. It went to trial in April 2024 and ended with a hung jury, trial 2 ended with a not guilty verdict in April 2025, and now there are 4 ongoing lawsuits: 2 filed against Karen (wrongful death and defamation) and 2 filed by her (1 against the police departments and 1 against the witnesses who testified against her and the individual police who investigated her). It’s been messy.
So it’s unsurprising that some pollsters decided it might be interesting to get a pulse check on how the public was feeling about this. So what did they find?
The Headline
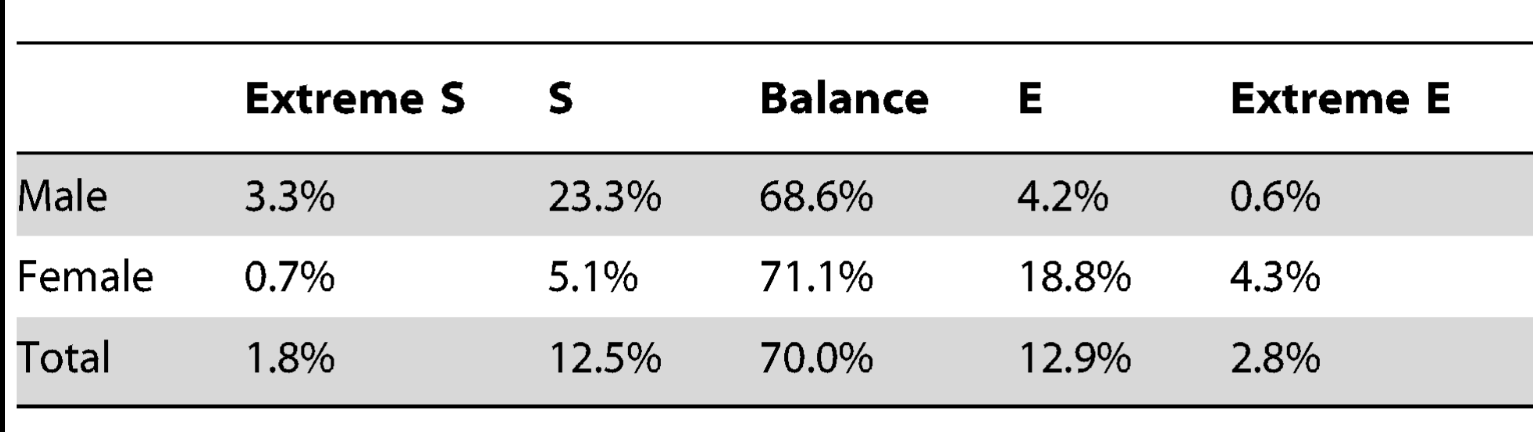
The marquee finding here came from a question in the Bay State poll about the Karen Read case. The first question asks people how much they’ve heard about the case, and for those who had heard at least something about the case, the second question asks the following “Do you believe police concealed evidence in this case or do you not have an opinion on this?” Across the board, just about 70% of people said definitely or probably, with about 6% of people saying no, and another chunk saying they weren’t sure. The skepticism of police was spread out across party affiliation:
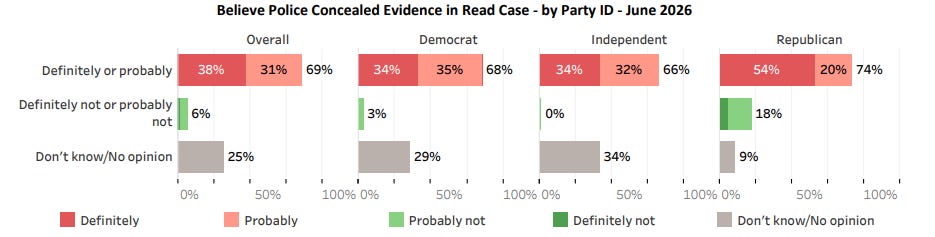
While most people got interested in the low level of support shown for the police here, I’ll admit my eyes were immediately drawn to the specific wording of the question. As someone who has watched this story develop over the last 4.5 years, I was surprised to see the poll specifically asked about the police concealing evidence. From my perspective, the main claim from the Read camp has always been that the police planted evidence…a somewhat different claim.
I reached out to the polls main contact at UNH, Dr Andrew Smith, to inquire about the wording, and he sent me a very nice response letting me know that the poll was developed in conjunction with Channel 7 and he did not recall any particular discussion about the concealed vs planted wording.
This surprised me a little to hear, but I think it points to how muddy things have gotten over the last few years, even for a group like Channel 7. From my perspective, I’ve seen a few separate claims develop out of Reads camp over time, and I think both she and her supporters would admit some of them are more important to her story than others:
- Police planting evidence: When John O’Keefe’s body was found on the lawn of 34 Fairview Rd in the early morning hours of January 29th, 2022, he was under a coating of snow in the spot where (by her own admission) Karen Read had dropped him off a few hours earlier. Her car would be found with a broken taillight, and her taillight pieces would be recovered from the area where the body was found, buried under the snow. His DNA and a hair would be found on her bumper, along with some glass. The state’s case is she hit him with her car, her supporters say he was killed elsewhere and moved to that spot. Thus, an absolute lynchpin of her defense is that those taillight pieces, that hair, and that glass were planted. There aren’t really a lot of ways around the planting claim here, if nothing was planted, it’s hard to see how she is innocent.
- Failure to investigate: Karen has filed suit stating police were biased against her and failed to investigate other possible suspects in the case.
- Bad investigative practices: Karen and her team have raised concerns about the way evidence was collected that morning during the blizzard that was happening
- Failure to turn over evidence: During the pre-trial it was claimed some evidence wasn’t turned over in a timely fashion, so there is some argument here, but it’s notable that most concealed evidence claims are about evidence that emerges after trial. It was specifically ruled by a judge this evidence 1. wasn’t exculpatory and 2. wasn’t prejudicial regardless because she got it prior to trial. But it is possible people were thinking of this.
I will note that these are allegations currently making their way through the court system, none of them have actually been proven, and for the sake of brevity, I am leaving a lot of details out here. If you are very curious, you can read Karen’s lawsuit against the witnesses/the police here and here, or the most robust Yes, Karen Read Did It post I’ve found.
From a survey question wording perspective, however, I am trying to make the point that the claim that the police concealed evidence has not often been used in this case, at least not in a legally relevant way. In fact, I searched the lawsuit Karen filed against the witnesses and the police officers for the word “concealed” and only found one instance of it2. Amusingly, it was in a sentence that accused the police of trying to “conceal the tampering with and planting of taillight material”. The word “planting” on the other hand appears 16 times in the filing. I think I am safe in my claim that planting evidence is the key accusation here. Karen makes it the key claim in her lawsuit. Critics of Karen make disproving it a key point in their debunking posts.
Why it Matters
Ok, so why does this matter? Aren’t “concealed” and “planted” close enough? Well, if you’ve done any sort of survey design, you know that small wording choices can matter a lot in the way people respond. Back when I used to do my Intro to Internet Science class, I would use the example of a 2010 CBS poll that found that swapping out the phrase “homosexuals” for “gays and lesbians” caused a jump in support for their participation in military service:

In a famous poll in 1989, it was found that asking voters about “assistance to the poor” vs “welfare” could cause a 40 point swing in support. Asking people if they think we should forbid something gets about 20% less support than asking if you should not allow something. So it’s not crazy to think that changing the question from “Do you believe police concealed evidence” to “Do you believe police planted evidence” could cause a change as well, and possibly a large one.
My suspicion is that when people answered this question, they were not sticking to a strict definition of the word conceal as in “the police had evidence and they hid it from Karen Read and her team”. My guess is they were interpreting the question to include everything in items 2-4 above, with a dash of “I don’t know what I don’t know”. Saying evidence is “concealed” is easier to attach a vague feeling too, which matters when 70% of the people answering the question say they’ve heard “some” or “not too much” about the case.
Because again, the taillight being planted is a lynchpin claim here. If the taillight was not planted, then the police showed up and found a woman with a busted taillight and a dead body surrounded by pieces of said taillight3. Their subsequent actions all look much more understandable in that light. It’s like if you showed up to find someone with a smoking gun in their hands. If the taillight was planted however, the concealing evidence actually seems like the least of your problems.
My guess as to where this wording came from? After 3+ years of headlines, I don’t think people are entirely keeping straight what is being claimed, or have a very broad list of concerns. When I asked ClaudeAI for its take, it actually got confused multiple times trying to follow the coverage. When I asked it for one summary word for a question, it did suggest “cover-up”, but I actually know that Channel 7 wouldn’t have used that word because a rival station (Channel 10) runs their coverage under “Canton Cover-Up”. It’s possible somebody just grabbed a synonym.
This is all a very long way of saying I would love to see this poll rerun with a question about evidence planting to test my theory that the term “planted” would be seen as a more specific claim and would potentially change the agreement structure.
So What About the Rest of This Poll aka How Does this Compare to Prior Polling?
While the Karen Read specific questions are getting all the headlines, I was interested in the rest of the poll that actually showed overall attitudes towards police in Massachusetts when Karen Read wasn’t mentioned.
This was actually pretty straightforward to compare nationally because for at least 4 of the police questions the Pew Research Group asks the same questions, though on a 4 point scale rather than a 5 point scale. Here’s the comparison:
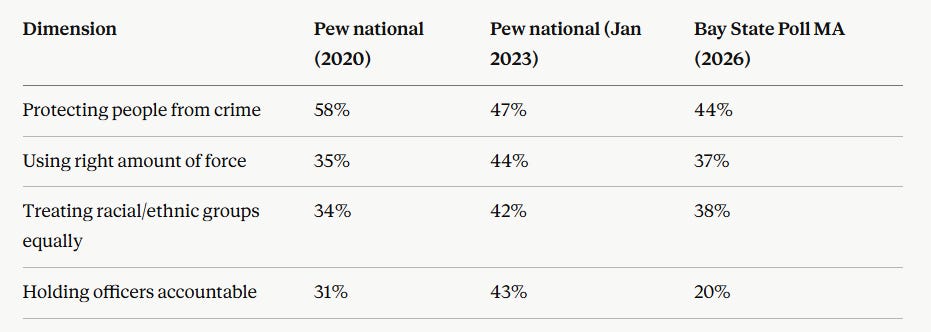
The major difference here is the “holding officers accountable” part, which seems reasonable.
I was also curious if there were any MA specific numbers from any of the George Floyd era, and I dug up a Suffolk University poll from June 2020 and used it to compare the police numbers we’re seeing now to the ones we were seeing then. The methodology here was really different (a basic yes/no, whereas the Bay state Poll is a 5 point scale), but here’s my attempt at a comparison:
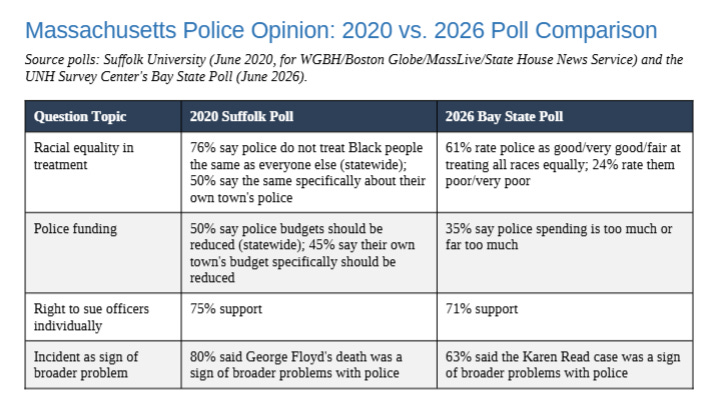
Note, for emphasis: these are different pollsters, in different years, with different question scales, and different distances from the events. Generalize at your own risk.
There were also some other questions with no direct 2020 comparison such as “would you feel safe calling 911” (93% said yes).
My Thoughts
Overall I thought this was an interesting idea for a poll and an interesting set of results, though again, I would have liked to see the question about evidence worded a bit differently to address the specifics of the case. Despite heavy media coverage, I think a lot of details ran together for people, as evidenced by AI being unable to keep details straight when called on to summarize the case for concealed evidence.
I would like to see this both out of personal curiosity as someone in the area, and as someone who is interested in how much poll wording changes can swing answers. Is this one of those distinction-without-a-difference type wording changes, or (as I suspect) would we see a bigger swing in public perception if people were called on to make (what they would likely perceive as) a more specific claim?
One can wonder.
The survey started with 700ish people and then excluded anyone who hadn’t heard anything about the Karen Read case or wasn’t sure if they had, about 8% of the sample. The subsequent 2 questions were answered by the remaining 652 people.
I couldn’t find a searchable copy of the more recent lawsuit, but a quick peruse shows the garage footage is again noted as the only potentially concealed evidence. Everything else is about bias, planting evidence or failing to investigate.
It’s important to note Read herself has never offered an alternate version for how the taillight got there other than being planted, it was her first time at the house.