Birth order is a hot topic in my family. I’m the oldest of four, and for as long as I can remember I’ve been grousing that being the oldest child is a bad deal. Your parents try out all their bright shiny untested parenting theories on you, relaxing the rules for all the subsequent kids, you’re held responsible for everything, and generally it’s just not faaaaaaaaaaaaaaaaair. Of course all this extra pressure does have some upsides later in life, like an increased likelihood of being a CEO or President. Anyway, given how often I’ve brought this up over the years, my parents (a youngest-of-3 and middle-of-5, respectively) were quick to point me to this article about the disappearance of the middle child in the US. After reading this article and the AVIs post about birthrates earlier this week, I went on a bit of a Google-bender on the whole topic. I figured I’d do a roundup of the most interesting numbers I found.
A quick note before I get started: for ease-of-counting purposes, fertility rates and family sizes are normally measured by “number of kids per woman”. This makes the data less messy, since you don’t have to worry about controlling for people who have children with multiple partners. However, it does often make discussions of fertility rates sound as though women are having kids in a vacuum and that men have nothing to do with it. This is simply not true. Social and economic pressures that encourage women to have fewer kids are almost certainly impacting men as well, and the compounding effect can decrease birthrates quite quickly. So basically while I’ll be making a lot of references to women below, that’s just a data thing, not a “this is how it actually works” thing. Also, I’m going to mostly stick to numbers here as opposed to speculate on causality, because that’s just how I roll.
Alright, with that out of the way, let’s get started!
- Birthrates are declining worldwide. It’s not surprising that most discussions of birthrates and family size in the US immediately start with a discussion of the factors in the US that could have led to falling birthrates. However, it’s important to realize that declining fertility rates is a global phenomena. Our World in Data shows that in 1950, the total fertility rate (TFR) for women everywhere was 5 children. In 2015, it was at 2.49. In that same time period, the US went from about 3 children per woman to 1.84. This is notable because sometimes the explanations that are offered for declining birthrates in the US (like expensive daycare or lack of parental leave policies) don’t hold when you compare them to other countries. Sweden and Denmark are both known for having robust childcare/time off policies for parents, yet their fertility rates are identical to or lower than ours. Whatever it is that pushes birth rates lower, it seems to have a pretty cross cultural impact.
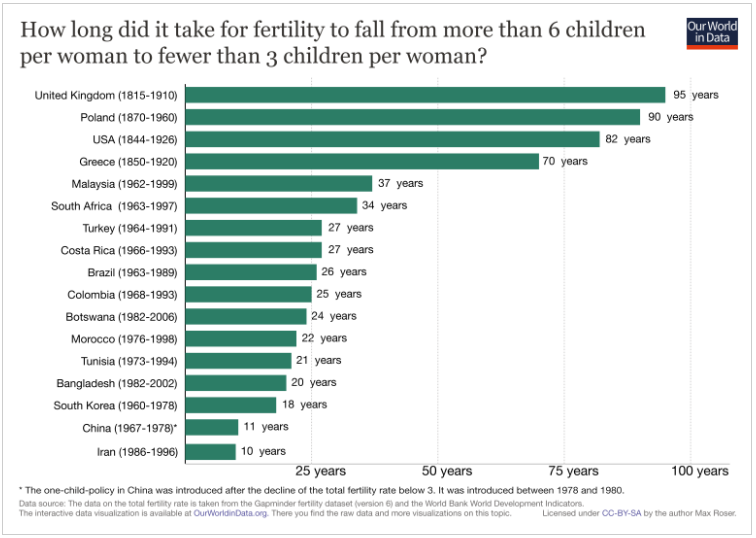
- Birthrates can fall fast. Like, really really fast. Growing up in the US, I always thought of birthrates as something that sort of slowly trended downward as countries grew more developed. What I didn’t realize is that it doesn’t always happen this way. Our World in Data has an interesting chart that shows how long it took for various countries to go from a birthrate of 6 or more children to 3 or fewer:
 What’s stunning about this is that some of these numbers are half a generation. For birthrates to fall that quickly in Iran for example, it doesn’t just mean women were having fewer children than their mothers, it means they started having fewer children than their older sisters. In case you’re curious if these trends were just a product of instability in those countries during those times: today the birthrate in Bangladesh is 2.17, South Korea is 1.26, China is 1.60, Iran is 1.97 (per Wiki/CIA Factbook). It seems like all the downward trends shown here kept up or accelerated. China obviously made this a formal policy, but it does not appear the other countries did. I found this interesting because we often hear about subtle factors/cultural messages that impact birthrates, but there’s nothing subtle about these drop offs.
What’s stunning about this is that some of these numbers are half a generation. For birthrates to fall that quickly in Iran for example, it doesn’t just mean women were having fewer children than their mothers, it means they started having fewer children than their older sisters. In case you’re curious if these trends were just a product of instability in those countries during those times: today the birthrate in Bangladesh is 2.17, South Korea is 1.26, China is 1.60, Iran is 1.97 (per Wiki/CIA Factbook). It seems like all the downward trends shown here kept up or accelerated. China obviously made this a formal policy, but it does not appear the other countries did. I found this interesting because we often hear about subtle factors/cultural messages that impact birthrates, but there’s nothing subtle about these drop offs.
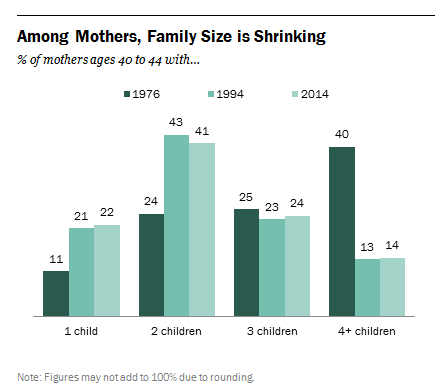
- A reduction in those having large families impacts the average as much (or more) than the number of women going childless. One of the first things that comes up when you talk about dropping fertility rates is the number of women who remain childless. While childless women certainly cause a drop in fertility rates, it’s important to note that they are also lowered by the number of women who don’t have large numbers of kids. I don’t have the numbers, but I would guess that the countries in point #2 ended up with lower fertility rates not because of a surge in childless women, but by a major decrease in women having 6 or more children. If we look at the change in family size in the US since 1976, the most notable drop is women having 4+ kids. From Pew Research:
 My first takeaway from this is that the appeal of having 3 children is timeless. My second takeaway is that it appears a large number of people aren’t crazy about having a large family. This matches my experience, because while you often hear people ask those without children or with one child “why don’t you have more kids?” you don’t often hear people ask those with 2 children the same thing. My friends with 3 children inform me that they actually start getting”you’re not having more are you?” type comments and I’d imagine those with 4 or more get the same thing routinely. Now I grew up going to Baptist school and my siblings were all home schooled at some point, so I am well aware that there are still groups that support/encourage big families. However, even among those who like “big families”, I think the perception of what “big” is has shrunk. I have friends who talked incessantly about wanting big families, married early and were stay at home moms, and none of them have more than 5 children. Most of us don’t have to go more than a generation or two back in our family trees to find a family of 5 kids or more. It seems like even those who want a big family think of it in terms of “more children than others” as opposed to an absolute number. Yes, the Duggars exist, but they are so rare they got a TV show out of the whole thing.
My first takeaway from this is that the appeal of having 3 children is timeless. My second takeaway is that it appears a large number of people aren’t crazy about having a large family. This matches my experience, because while you often hear people ask those without children or with one child “why don’t you have more kids?” you don’t often hear people ask those with 2 children the same thing. My friends with 3 children inform me that they actually start getting”you’re not having more are you?” type comments and I’d imagine those with 4 or more get the same thing routinely. Now I grew up going to Baptist school and my siblings were all home schooled at some point, so I am well aware that there are still groups that support/encourage big families. However, even among those who like “big families”, I think the perception of what “big” is has shrunk. I have friends who talked incessantly about wanting big families, married early and were stay at home moms, and none of them have more than 5 children. Most of us don’t have to go more than a generation or two back in our family trees to find a family of 5 kids or more. It seems like even those who want a big family think of it in terms of “more children than others” as opposed to an absolute number. Yes, the Duggars exist, but they are so rare they got a TV show out of the whole thing.
- International adoption likely doesn’t get factored in. As mentioned above, I probably know an above average number of people with 4+ children. Many of these families have a mix of biological and adopted children, frequently foreign adoptions. According the the CDC though, it doesn’t appear those adopted children are not counted in birthrate data, as they calculate that off of birth certificates issued for live births taking place in the US during a given year. Now of course this isn’t a huge impact on overall numbers: there are currently only about 5,000 international adoptions/year in the US, down from a high of 15,000 or so, vs 4,000,000 overall births. However, it is interesting to note that “number of kids” does not always equal birthrate. Since the US is the biggest adopter of foreign children in the world, it is a thing to keep in mind here.
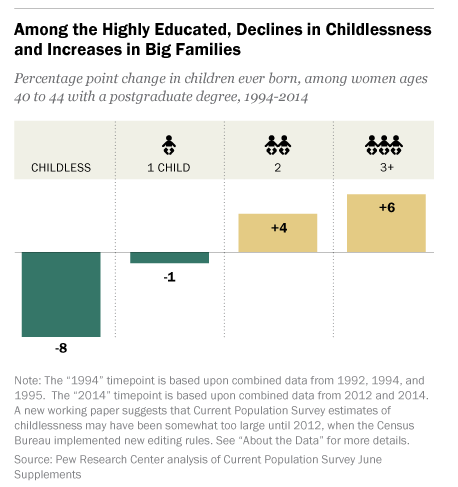
- The demographics of who doesn’t have kids are changing When you mention “women without children” the vision that immediately springs to mind is a well educated white woman who put her career first. Interestingly enough, this stereotype is increasingly untrue, and is changing in many countries. According to Pew Research, childlessness among women with post-graduate degrees has dropped quite a bit in the last 20 years, and the number of women in that group with 3+ kids has gone up:
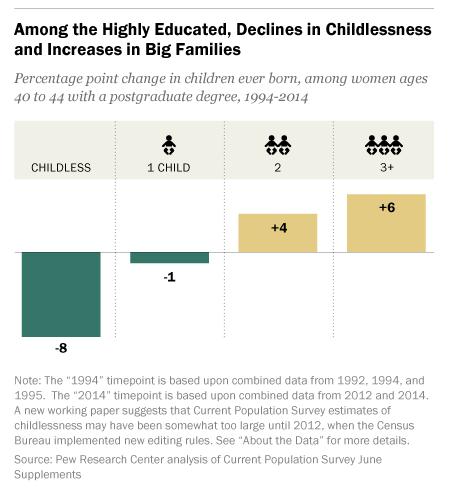 According to the Economist, in Finland women with a basic education are less likely to have children than their more educated peers, and other countries are trending the same way. The US is nowhere near flipping, but it is an interesting trend to keep an eye on. Historically, education has always been associated with dropping fertility rates, so this would be huge if it switched.
According to the Economist, in Finland women with a basic education are less likely to have children than their more educated peers, and other countries are trending the same way. The US is nowhere near flipping, but it is an interesting trend to keep an eye on. Historically, education has always been associated with dropping fertility rates, so this would be huge if it switched.
Overall, I thought the data out there on the topic was pretty interesting. The worldwide trends make it interesting to try to come up with a hypothesis that fits all scenarios. For example, we know that effective birth control must impact the number of children people have, but Britain and the US both had birthrates under 3 decades before oral contraceptives came in to play. Economic resources must play a part, and yet it’s the richest countries that have the lowest birthrates. Wealth is sometimes linked to higher numbers of children (particularly among men), but sometimes it’s not. Education always lowers fertility rates, except that’s started to reverse. Things to puzzle over.







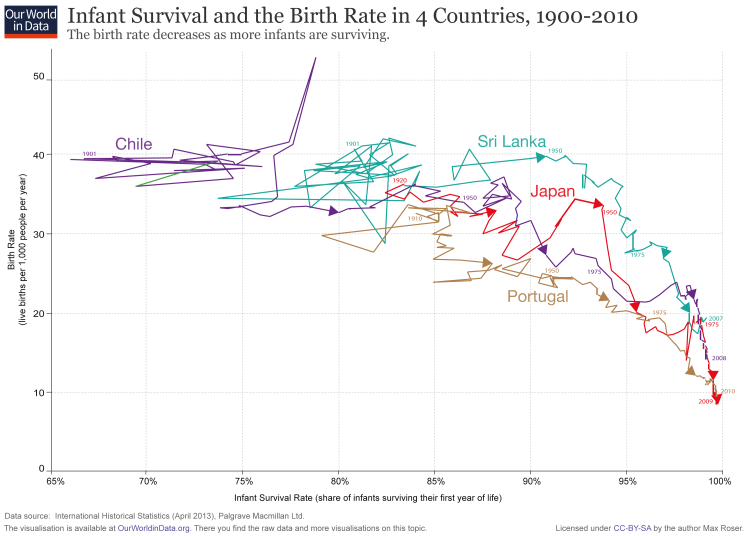 This is a good reminder that countries with total fertility rates of 6 children/woman or more almost never result in families of 6 adult children, and that our drops in fertility rate aren’t always as dramatic as they sound. For example, in the year 1800 in the US, the fertility rate was nearly 7 children/woman, while today it is just under 2. However, if you factor child mortality in, the drop is much less dramatic:
This is a good reminder that countries with total fertility rates of 6 children/woman or more almost never result in families of 6 adult children, and that our drops in fertility rate aren’t always as dramatic as they sound. For example, in the year 1800 in the US, the fertility rate was nearly 7 children/woman, while today it is just under 2. However, if you factor child mortality in, the drop is much less dramatic:


{kind=link}