Welcome to the Calling Bullshit Read-Along based on the course of the same name from Carl Bergstorm and Jevin West at the University of Washington. Each week we’ll be talking about the readings and topics they laid out in their syllabus. If you missed my intro and want the full series index, click here or if you want to go back to Week 7 click here.
Well hello Week 8! How’s everyone doing this week? A quick programming note before we get going: the videos for the lectures for the Calling Bullshit class are starting to be posted on the website here. Check them out!
This week we’re taking a look at publication bias, and all the problems that can cause. And what is publication bias? As one of the readings so succinctly puts it, publication bias “arises when the probability that a scientific study is published is not independent of its results.” This is a problem because it not only skews our view of what the science actually says, but also is troubling because most of us have no way of gauging how extensive an issue it is. How do you go about figuring out what you’re not seeing?
Well, you can start with the first reading, the 2005 John Ioannidis paper “Why Most Published Research Findings are False“. This provocatively titled yet stats heavy paper does a deep dive in to the math behind publication and why our current research practices/statistical analysis methods may lead to lots of false positives reported in the literature. I find this paper so fascinating/important I actually did a seven part deep dive in to it a few months ago, because there’s a lot of statistical meat in there that I think is important. If that’s TL;DR for you though, here’s the recap: the statistical methods we use to control for false positives and false negatives (alpha and beta) are insufficient to capture all the factors that might make a paper more or less likely to reach an erroneous conclusion. Ioannidis lays out quite a few factors we should be looking at more closely such as:
- Prior probability of a positive result
- Sample size
- Effect size
- “Hotness” of field
- Bias
Ioannidis also flips the typical calculation of “false positive rate” or “false negative rate” to one that’s more useful for those of us reading a study: positive predictive value. This is the chance that any given study with a “positive” finding (as in a study that reports a correlation/significant difference, not necessarily a “positive” result in the happy sense) is actually correct. He adds all of the factors above (except hotness of field) in to the typical p-value calculation, and gives an example table of results. (1-beta is study power which includes sample size and effect size, R is his symbol for probability of a positive result, u is bias factor):
Not included is the “hotness” factor, where he points out that multiple research teams working on the same question will inevitably produce more false positives than just one team will. This is likely true even if you only consider volume of work, before you even get to corner cutting due to competition.
Ultimately, Ioannidis argues that we need bigger sample sizes, more accountability aimed at reducing bias (such as telling others your research methods up front or trial pre-registration), and to stop rewarding researchers only for being the first to find something (this is aimed at both the public and at journal editors). He also makes a good case that fields should be setting their own “pre-study odds” numbers and that researchers should have to factor in how often they should be getting null results.
It’s a short paper that packs a punch, and I recommend it.
Taking the issues a step further is a real life investigation contained in the next reading “Selective Publication of Antidepressant Trials and Its Influence on Apparent Efficacy” from Turner et al in the New England Journal of Medicine. They reviewed all the industry sponsored antidepressant trials that had pre-registered with the FDA, and then reviewed journals to see which ones got published. Since the FDA gets the results regardless of publication, this was a chance to see what was made it to press and what didn’t. The results were disappointing, but probably not surprising:
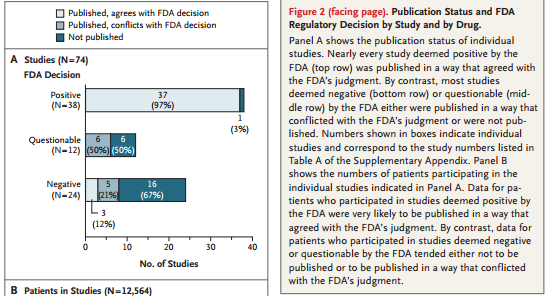
Figure 2 from “Selective Publication of Antidepressant Trials and Its Influence on Apparent Efficacy“
Positive results that showed the drugs worked were almost always published, negative results that showed no difference from placebo often went unpublished. Now the study authors did note they don’t know why this is, they couldn’t differentiate between the “file drawer” effect (where researchers put negative findings in their drawer and don’t publish them) and journals that rejected papers with null results. It seems likely both may be a problem. The study authors also found that the positive papers were presented as very positive, whereas some of the negative papers had “bundled” their results.
In defense of the anti-depressants and their makers, the study authors did find that a meta-analysis of all the results generally showed the drugs were superior to a placebo. Their concern was the magnitude of the effect may have been overstated. By not having many negative results to look it, the positive results are never balanced out and it appears the drugs are much more effective than they actually are.
The last reading is “Publication bias and the canonization of false facts.“by Nissen et al, a pretty in depth look at the effects of publication bias on our ability to distinguish between true and false facts. They set out to create a model of how we move an idea between theory and “established fact” through scientific investigation and publication, and then test what publication bias would do to that process. A quick caveat from the end of the paper I want to give up front: this model is supposed to represent the trajectory of investigations in to “modest” facts, not highly political or big/sticky problems. Those beasts have their own trajectory, much of which has little to do with publication issues. What we’re talking about here is the type of fact that would get included in a textbook with no footnote/caveat after 12 or so supportive papers.
They start out by looking at the overwhelming bias towards publishing “positive” findings. Those papers that find a correlation, reject the null hypothesis, or find statistically significant differences are all considered “positive” findings. Almost 80% of all published papers are “positive” findings, and in some fields this is as high as 90%. While hypothetically this could mean that researchers just pick really good questions, the Turner et al paper and the Ioannidis analysis suggest that this is probably not the full story. “Negative” findings (those that fail to reject the null or find no correlation or difference) just aren’t published as often as positive ones. Now again, it’s hard to tell if this is the journals not publishing or researchers not submitting, or a vicious circle where everyone blames everyone else, but here we are.
The paper goes on to develop a model to test how often this type of bias may lead to the canonization of false facts. If negative studies are rarely published and almost no one knows how many might be out there, it stands to reason that at least some “established facts” are merely those theories whose counter-evidence is sitting in a file drawer. The authors base their model on the idea that every positive publication will increase belief, and negative ones will decrease it, but they ALSO assume we are all Bayesians about these things and constantly updating our priors. In other words, our chances of believing in a particular fact as more studies get published probably look a bit like that line in red:
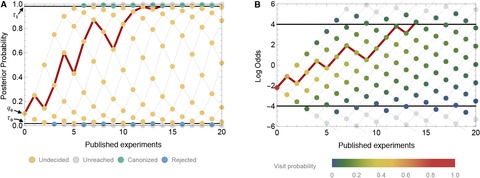
Figure 2 from “Research: Publication bias and the canonization of false facts“
This is probably a good time to mention that the initial model was designed only to look at publication bias, they get to other biases later. They assumed that the outcomes of studies that reach erroneous conclusions are all due to random chance, and that the beliefs in question were based only on the published literature.
The building of the model was pretty interesting, so you should definitely check that out if you like that sort of thing. Overall though, it is the conclusions that I want to focus on. A few things they found:
- True findings were almost always canonized
- False findings were canonized more often if the “negative” publication rate was low
- High standards for evidence and well designed experiments are not enough to overcome publication bias/reporting negative results
That last point is particularly interesting to me. We often ask for “better studies” to establish certain facts, but this model suggests that even great studies are misleading if we’re seeing a non-random sample. Indeed, their model showed that if we have a negative publication rate of under 20%, false facts would be canonized despite high evidence standards. This is particularly alarming since the antidepressant study found around a 10% negative publication rate.
To depress us even further, the authors then decided to add researcher bias in to the mix and put some p-hacking in to play. Below is their graph of the likelihood of canonizing a false fact vs the actual false positive rate (alpha). The lightest line is what happens wehn alpha = .05 (a common cut off), and each darker line shows what happens if people are monkeying around to get more positive results than they should:
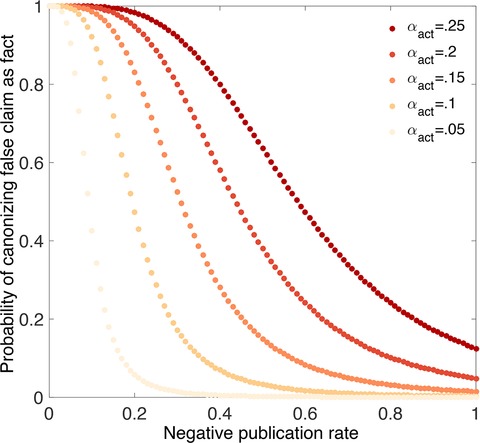
Figure 8 from “Research: Publication bias and the canonization of false facts”
Well that’s not good.
On the plus side, the paper ends by throwing yet another interesting parameter in to the mix. What happens if people start publishing contradictory evidence when a fact is close to being canonized? While it would be ideal if negative results were published in large numbers up front, does last minute pushback work? According to the model, yes, though not perfectly. This is a ray of hope because it seems like in at least some fields, this is what happens. Negative results that may have been put in the file drawer or considered uninteresting when a theory was new can suddenly become quite interesting if they contradict the current wisdom.
After presenting all sorts of evidence that publishing more negative findings is a good thing, the discussion section of the paper goes in to some of the counterarguments. These are:
- Negative findings may lead to more true facts being rejected
- Publishing too many papers may make the scientific evidence really hard to wade through
- Time spent writing up negative results may take researchers away from other work
The model created here predicts that #1 is not true, and #2 and #3 are still fairly speculative. On the plus side, the researchers do point to some good news about our current publication practices that may make the situation better than the model predicts:
- Not all results are binary positive/negative They point out that if results are continuous, you could get “positive” findings that contradict each other. For example, if a correlation was positive in one paper and negative in another paper, it would be easy to conclude later that there was no real effect even without any “negative” findings to balance things out.
- Researchers drop theories on their own Even if there is publication bias and p-hacking, most researchers are going to figure out that they are spending a lot more time getting some positive results than others, and may drop lines of inquiry on their own.
- Symmetry may not be necessary The model assumes that we need equal certainty to reject or accept a claim, but this may not be true. If we reject facts more easily than we accept them, the model may look different.
- Results are interconnected The model here assumes that each “fact” is independent and only reliant on studies that specifically address it. In reality, many facts have related/supporting facts, and if one of those supporting facts gets disproved it may cast doubt on everything around it.
Okay, so what else can we do? Well, first recognize the importance of “negative” findings. While “we found nothing” is not exciting, it is important data. They call on journal editors to consider the possible damage of considering such papers uninteresting. Next, they point to new journals springing up dedicated just to “negative results” as a good trend. They also suggest that perhaps some negative findings should be published as pre-prints without peer review. This wouldn’t help settle questions, but it would give people a sense of what else might be out there, and it would settle some of the time commitment problems.
Finally a caveat which I mentioned at the beginning but is worth repeating: this model was created with “modest” facts in mind, not huge sticky social/public health problems. When a problem has a huge public interest/impact (like say smoking and lung cancer links) people on both sides come out of the woodwork to publish papers and duke it out. Those issues probably operate under very different conditions than less glamorous topics.
Okay, over 2000 words later, we’re done for this week! Next week we’ll look at an even darker side of this topic: predatory publishing and researcher misconduct. Stay tuned!
Week 9 is up! Read it here.
