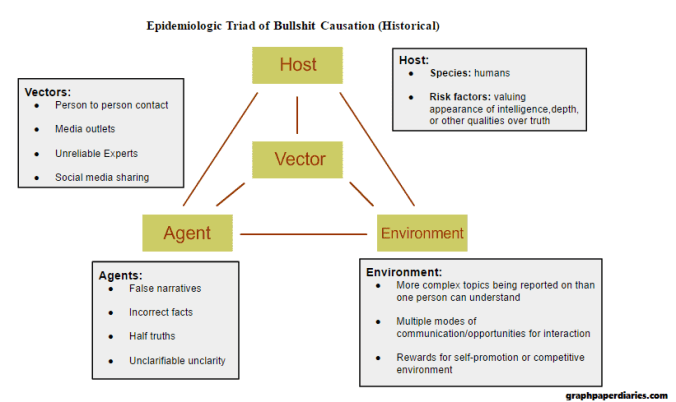
Welcome to the Calling Bullshit Read-Along based on the course of the same name from Carl Bergstorm and Jevin West at the University of Washington. Each week we’ll be talking about the readings and topics they laid out in their syllabus. If you missed my intro and want the full series index, click here or if you want to go back to Week 11 click here.
Well guys, we made it! Week 12, the very last class. Awwwwwwwe, time flies when you’re having fun.
This week we’re going to take a look at refuting bullshit, and as usual we have some good readings to guide us. Amusingly, there’s only 3 readings this week, which puts the course total for “readings about bullshit” at an order of magnitude higher than the count for “readings about refuting bullshit”. I am now dubbing this the “Bullshit Assignment Asymmetry Principle: In any class about bullshit, the number of readings dedicated to learning about bullshit will be an order of magnitude higher than the number of readings dedicated to refuting it”. Can’t refute what you can’t see.
Okay, so first up in the readings is the short-but-awesome “Debunking Handbook” by John Cook and Stephan Lewandowsky. This pamphlet lays out a compelling case that truly debunking a bad fact is a lot harder than it looks and must be handled with care. When most of us encounter an error, we believe throwing information at the problem will help. The Debunking Handbook points out a few issues:
- Don’t make the falsehood familiar A familiar fact feels more true than an unfamiliar one, even if we’re only familiar with it because it’s an error
- Keep it simple Overly complicated debunkings confuse people and don’t work
- Watch the worldview Remember that sometimes you’re arguing against a worldview rather than a fact, and tread lightly
- Supply an alternative explanation Stating “that’s not true” is unlikely to work without replacing with an alternative
They even give some graphic/space arranging advice for those trying to put together a good debunking. Check it out.
The next paper is a different version of calling bullshit that starts to tread in to the academic trolling territory we discussed a few weeks ago, but stops short by letting everyone be in on the joke. It’s the paper “Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: An argument for multiple comparisons correction“, and it answers the age old question of “what happens when you put a dead fish in an MRI machine”. As it turns out, more than you’d think. It turns out they discovered statistically significant brain activity, even after death.
Or did they?
As the authors point out, when you are looking at 130,000 voxels, there’s going to be “significant” noise somewhere, even in a dead fish. Even using a p-value of .001, you still will get some significant voxel activity and some of those will almost certainly be near each other, leading to the “proof” that there is brain activity. There are statistical methods that can be used to correct for this, and they are widely available, but often underused.
By using traditional methods in such an absurd circumstance, the authors are able to call out a bad practice while not targeting anyone individually. Additionally, they make everyone a little more aware of the problem (reviewers and authors) in a memorable way. They also followed the debunking schema above and immediately provided alternative methods for analysis. Overall, a good way of calling bullshit with minimal fallout.
Finally, we have one more paper “Athletics: Momentous sprint at the 2156 Olympics?” and its corresponding Calling Bullshit Case Study. This paper used a model to determine that women would start beating men in the 100 meter dash on an Olympic level in 2156. While the suspicion appears to be that the authors were not entirely serious and meant this to be a critique of modeling in general, some of the responses were pretty great. It turns out this model also proves that by 2636 races will end before they begin. I, for one, am looking forward to this teleportation breakthrough.
Yet again here we see a good example of what is sometimes called “highlighting absurdity by being absurd”. Saying that someone is extrapolating beyond the scope of their model sounds like a nitpicky math argument (ask me how I know this), but pointing out the techniques being used can prove ridiculous things makes your case pretty hard to argue with.
Ultimately, a lot of calling bullshit in statistics or science gets down to a lot of the same things we have to consider when confronting any other bad behavior in life. Is it worth it? Is this the hill to die on? Is the problem frequent? Are you attacking the problem or the person? Do you know the person? Is anyone listening to the person/do they have a big platform? Is there a chance of making a difference? Are you sure you are not guilty of the same thing you’re accusing someone else of? Can humor get the job done?
While it’s hard to set any universal rules, these are about as close as I get:
- Media outlets are almost always fair game They have a wide reach and are (at least ostensibly) aiming to inform, so they should have bullshit called whenever you see it, especially for factual inaccuracies.
- Don’t ascribe motive I’ve seen a lot of people ruin a good debunking by immediately informing the person that they shared some incorrect fact because they are hopelessly biased/partisan/a paid shill/sheeple. People understandably get annoyed by that, and they react more defensively because of it. Even if you’re right about the fact in question, if you’re wrong about their motive that’s all they’ll remember. Don’t go there.
- Watch what you share Seriously, if everyone just did this one, we wouldn’t be in this mess.
- Your field needs you Every field has its own particular brand of bullshit, and having people from within that field call bullshit helps immensely.
- Strive for improvement Reading things like the debunking handbook and almost any of the readings in this course will help you up your game. Some ways of calling bullshit simply are more effective than others, and learning how to improve can be immensely helpful.
Okay, well that’s all I’ve got!
Since this is the end of the line for the class, I want to take this opportunity to thank Professors Bergstrom and West for putting this whole syllabus and class together, for making it publicly available, and for sharing the links to my read-along. I’d also like to thank all the fun people who have commented on Twitter, the blog or sent me messages….I’m glad people enjoyed this series!
If you’d like to keep up with the Calling Bullshit class, they have twitter, facebook, and a mailing list.
If you’d like to keep up with me, then you can either subscribe to the blog in the sidebar, or follow me on Twitter.
Thanks everyone and happy debunking!
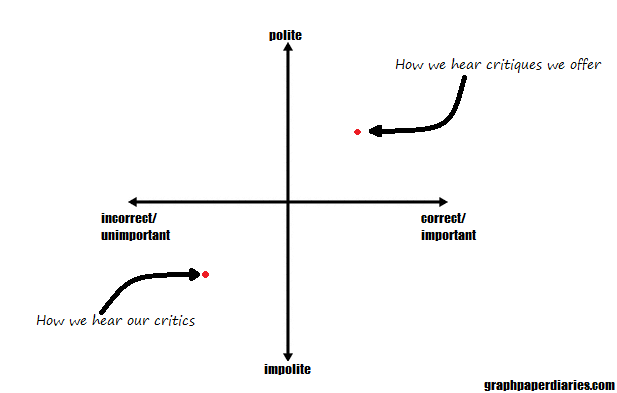

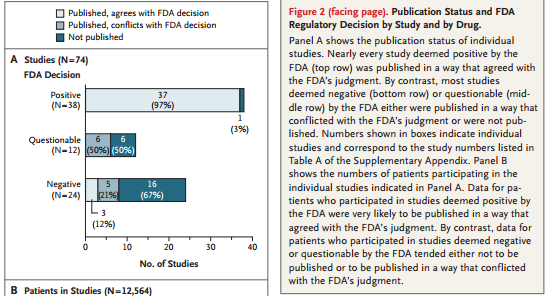








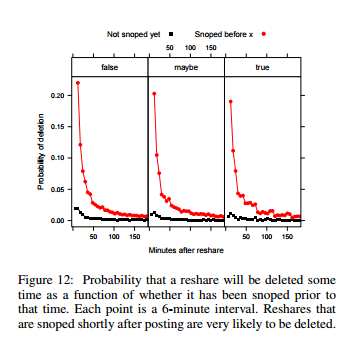 In terms of getting people to delete their posts, the most successful debunking links were things like “
In terms of getting people to delete their posts, the most successful debunking links were things like “