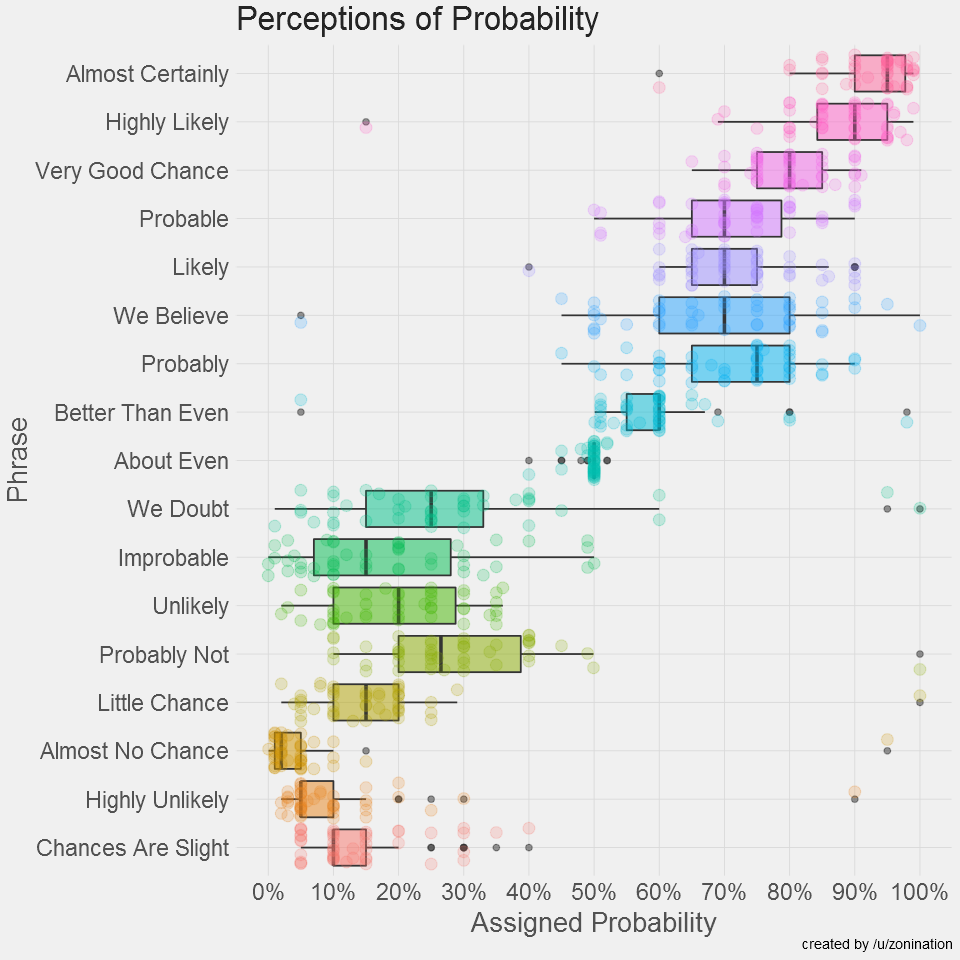
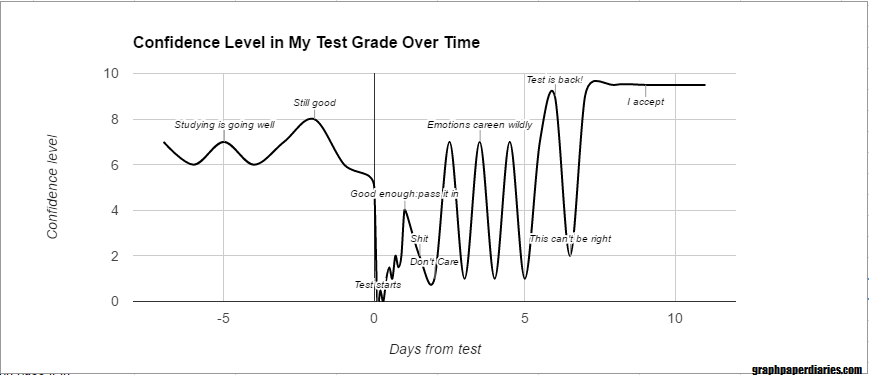
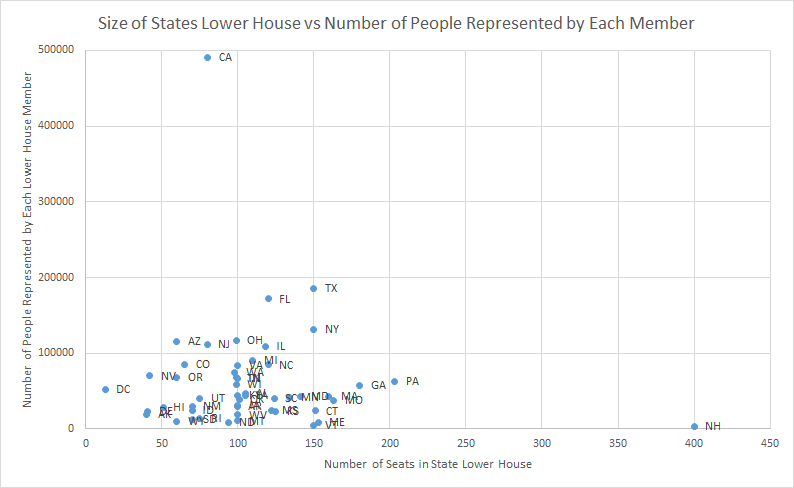
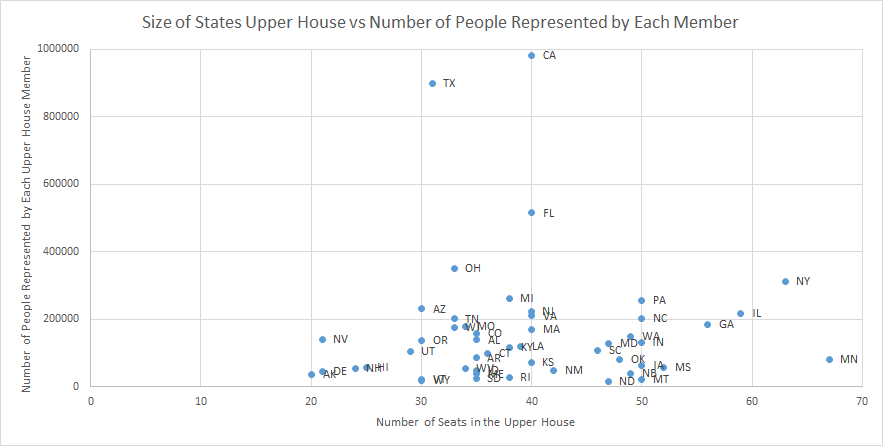
I’ve been playing/listening to a lot of Zombies, Run! lately, and for a little extra inspiration I decided to pull out my copy of “Born to Run” and reread it. Part way through the book I came across a statistic I thought was provocative enough that I decided to investigate it. In a chapter about the history of American distance running, McDougall is talking about the Greater Boston track club and says the following:
“…by the early ’80s, the Greater Boston Track club had half a dozen guys who could run a 2:12 marathon. That’s six guys, in one amateur club, in one city. Twenty years later, you couldn’t find a single 2:12 marathoner anywhere in the country.”
Now this claim seemed incredible to me. Living in Boston, I’d imagine I’m exposed to more marathon talk every year than most people, and I had never heard this. I had assume that like most sports, those who participated in the 70s would be getting trounced by today’s high performance gear/nutrition/coached/sponsored athletes. Marathoning in particular seems like it would have benefited quite a bit from the entry of money in to the sport, given the training time required.
So what happened?
Well, the year 2000 happened, and it got everyone nervous.
First some background In order to make the US Olympic marathon team, you have to do two things 1) finish as one of the top 3 in a one off qualifying race 2) be under the Olympic qualifying time. In 1984, pro-marathoners were allowed to enter the Olympics. In 1988, the US started offering a cash prize for winning the Olympic trials. Here’s how the men did, starting from 1972:

I got the data from this website and the USATF. I noted a few things on the chart, but it’s worth spelling it out: the winners from 1976 and 1984 would have qualified for every team except 2008 and 2012. The 1980 winner would have qualified for every year except 2012, and that’s before you consider that the course was specifically chosen for speed after the year 2000 disaster.
So it appears to be relatively well supported that the guys who were running marathons for fun in the 70s really would keep pace with the guys today, which is pretty strange. It’s especially weird when you consider how much marathoning has taken off with the general public in that time. The best estimates I could find say that 25,000 people in the US finished a marathon in 1976, and by 2013 that number was up to about 550,000. You would think that would have swept up at least a few extra competitors, but it doesn’t look like it did. All that time and popularity and the winning time was 2 minutes faster for a 26 mile race.
For women it appears to be a slightly different story. Women got their start with marathoning a bit later than men, and as late as 1967 had to dodge race officials when they ran. Women’s marathoning was added to the Olympics in 1984, and here’s how the women did:

A bit more of a dropoff there.
If you’ve read Born to Run, you know that McDougall’s explanation for the failure to improve has two main threads: 1) that shoe companies potentially ruined our ability to run long distances and 2) that running long distances well requires you to have some fun with your running and should be built on community. Both seem plausible given the data, but I wanted to compare it to a different running event to see how it stacked up. I picked the 5000 m run since that’s the most commonly run race length in the US. The history of winning times is here, and the more recent times are here. It turns out the 5k hasn’t changed much either:

So that hasn’t changed much either….but there still wasn’t a year where we couldn’t field a team. Also complicating things is the different race strategies employed by 5000m runners vs marathon runners. To qualify for the 5k, you run the race twice in a matter of a few days. It is plausible that 5k runners don’t run faster than they have to in order to qualify. Marathon runners on the other hand may only run a few per year, especially at the Olympic level. They are more likely to go all out. Supporting this theory is how the runners do when they get to the Olympics. The last man to win a 5000m Olympic medal for the US is Paul Chelimo. He qualified with a 13:35 time, then ran a 13:03 in the Olympics for the silver medal. Ryan Hall on the other hand (the only American to ever run a sub 2:05 marathon), set the Olympic trials record in 2008 running a 2:09 marathon. He placed 10th in the Olympics with a 2:12. Galen Rupp won the bronze in Rio in 2016 with a time 1 minute faster than his qualifying time. I doubt that’s an unusual pattern….you have far more control over your time when you’re running 3 miles than when you’re running 26. To further parse it, I decided to pull the data from the Association of Road Racing Statisticians website and get ALL men from the US who had run a sub 2:12 marathon. Since McDougall’s original claim was that there were none to be found around the year 2000, I figured I’d see if this was true. Here’s the graph:

So he was exaggerating. There were 5.
Pedantry aside, there was a remarkable lack of good marathoners in those years, though it appeared the pendulum started to swing back. McDougall’s book came out in 2009 and was credited with a huge resurgence in interest in distance racing, so he may have partially caused that 2010-2014 spike. Regardless, it does not appear that Americans have recaptured whatever happened in the early 80s, even with the increase in nearly every resource that you would think would be helpful. Interestingly enough, two of the most dominate marathoners in the post-2000 spike (Khalid Khannouchi and Meb Keflezighi) came here in poverty as immigrants when they were 29 and 12, respectively. Between the two of them they are actually responsible for almost a third of the sub-2:12 marathons times posted between 2000 and 2015. It seems resources simply don’t help marathon times that much. Genetics may play a part, but it doesn’t explain why the US had such a drop off. As McDougall puts it “this isn’t about why other people got faster; it’s about why we got slower.”
So there may be something to McDougall’s theory, or there may be something about US running in general. It may be that money in other sports siphoned off potential runners, or it may be that our shoes screwed us or that camaraderie and love of the sport was more important than you’d think. Good runners may run fewer races these days, just out of fear that they’ll get injured. I don’t really know enough about it, but the stagnation is a little striking. It does look like there was a bit of an uptick after the year 2000 disaster….I suspect seeing the lack of good marathon runners encouraged a few who may have focused on other sports to dive in.
As an interesting data point for the camaraderie/community influence point, I did discover that women can no longer set a marathon world record in a race where men also run. From what I can tell, the governing bodies decided that being able to run with a faster field/pace yourself with men was such an advantage that it didn’t count. The difference is pretty stark (2:15 vs 2:17), so they may have a point. The year Paula Radcliffe set the 2:15 record in London, she was 16th overall and presumably had plenty of people to pace herself with. Marathoning does appear to be a sport where your competition is particularly important in driving you forward.
My one and only marathon experience biases me in this direction. In 2009 I ran the Cape Cod Marathon and finished second to last. At mile 18 or so, I had broken out in a rash from the unusually hot October sun, had burst in to tears and was ready to quit. It was at that moment that I came across another runner, also in tears due to a sore knee. We struck up a conversation and laughed/talked/yelled/cried at each other for the remaining 7 miles to the finish line. Despite my lack of bragging rights for my time I was overjoyed to have finished, especially when I realized over 400 people (a third of entrants) had dropped out. I know for a fact I would not have made it if I hadn’t run in to my new best friend at that moment of despair, and she readily admitted the same thing. McDougall makes the point that this type of companionship running is probably how our ancestors ran, though for things like food and safety as opposed to a shiny medal with the Dunkin Donuts logo. Does this sort of thing make a difference at the Olympic level? Who knows, but the data and anecdote does suggest there’s some interesting psychological stuff going on when you get to certain distances.
Race on folks, race on.