Welcome to the Calling Bullshit Read-Along based on the course of the same name from Carl Bergstorm and Jevin West at the University of Washington. Each week we’ll be talking about the readings and topics they laid out in their syllabus. If you missed my intro and want the full series index, click here or if you want to go back to Week 3 click here.
Well hello week 4! We’re a third of the way through the class, and this week we’re getting a crash course in correlation/causation confusion, starting with this adapted comic:

Man, am I glad we’re taking a look at this. Correlating variables is one of the most common statistical techniques there is, but it is also one of the most commonly confused. Any time two variables are correlated, there are actually quite a few possible explanations such as:
- Thing A caused Thing B (causality)
- Thing B caused Thing A (reversed causality)
- Thing A causes Thing B which then makes Thing A worse (bidirectional causality)
- Thing A causes Thing X causes Thing Y which ends up causing Thing B (indirect causality)
- Some other Thing C is causing both A and B (common cause)
- It’s due to chance (spurious or coincidental)
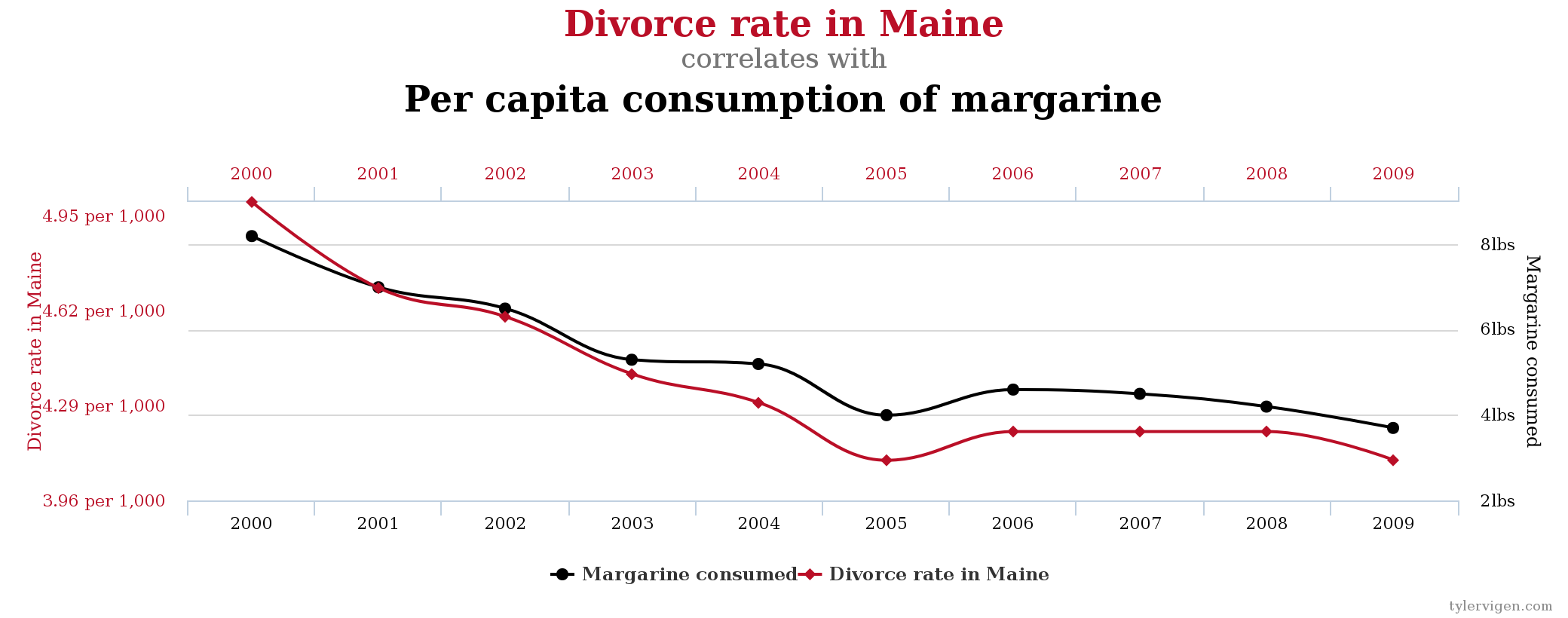
You can find examples of each here, but the highlight is definitely the Spurious Correlations website. Subjects include the theory that Nicolas Cage movies cause drownings and why you don’t want to eat margarine in Maine.
With that framing, the first reading is an interesting anecdote that highlights both correlation/causation confusion AND why sometimes it’s the uncorrelated variables that matter. In Milton Friedman’s thermostat analogy, Friedman ponders what would happen if you tried to analyze the relationship between indoor temperature, outdoor temperature and energy usage in a home. He points out that indoor temperature would be correlated with neither variable, as the whole point is to keep that constant. If you weren’t familiar with the system, you could conclude that using energy caused a drop in temperatures, and that the best way to stay warm would be to turn off the furnace. A good anecdote to keep in mind as it illustrates quite a few issues all at once.
Next up is the awesomely named paper “Storks Deliver Babies (p = 0.008)“. In it, Robert Mathews takes the birth rates in 17 European countries and correlates them with the approximate number of storks in each country and finds a correlation coefficient of .62. As the title of the paper suggests, this correlation is statistically significant. The author uses this to show the weaknesses of some traditional statistical analyses, and how easy it is to get ridiculous results that sound impressive.
Misleading statistics is also the subject of the Traffic Improvements case study, where a Seattle news station complained that a public works project cost $74 million but only made the average commute 2 seconds faster, leading to the conclusion that the spending was not correlated with any improvements. When you dig a bit deeper though, you discover that the volume the highway could accomodate rose by 30,000 cars/day. If you take cars/day as a variable, the spending was correlated with an improvement. This is a bit like the Milton Friedman thermostat example: just because a variable stays constant doesn’t mean it’s not involved. You have to look at the whole system.
Speaking of the whole system, I was interested to note that part way through the case study the Calling BS overlords cited Boston’s own Big Dig and mention that “Boston traffic got better”. As a daily commuter in to Boston, I would like to mention that looking at the whole system here also gives a slightly more complicated picture. While it is true that the Big Dig allowed more cars to move through the city underground, a Boston Globe report noted that this only helped traffic along the route that got worked on. Traffic elsewhere in the city (like say, the area I commute to) got much worse during this time frame, and Boston never lost it’s ranking as one of the most congested cities. Additionally, while the improvements made it possible to handle more cars on the road, the cost overrun severely hampered the cities ability to build or maintain it’s public transportation. Essentially by overspending on getting more cars through, the Big Dig made it necessary for more people to drive. Depending on which metric you pick, the Big Dig is both correlated with success AND failure…plus a tax bill I’m still chipping in money towards on TOP of what I pay for subpar commuter rail service. Not that I’m bitter or anything.
One interesting issue to note here is that sometimes even if journalists do a good job reporting on the nuances of correlation/causation, editors or headline writers can decide to muddy the issue. For example, Slate Star Codex did a great piece on how 4 different news outlets wrote a headline on the same study: 
Unless you were pretty on top of things, I don’t think most people would even recognize those middle two headlines were about the same study as the first and fourth. The Washington Post had to take a headline down after they had declared that if women wanted to stop violence against them they should get married. The new improved headline is below, but the original is circled in red:

It’s easy to think of headlines as innocuous if the text is good, but subtle shifts in headlines do color our perception of anything that comes after it. (I’ve collected most of my links on this research here)
Alright, back to the readings.
Our last piece goes back to 1897 and is written by Mr Correlation Coefficient himself: Karl Pearson. The math to work out the correlation coefficients had no sooner been done than Pearson started noticing people were misusing it. He was particularly concerned about people attributing biological causality to things that actually came from a common cause. Glad to see we’ve moved beyond that. Interestingly, history tells us that in Pearson’s day this was the fault of statisticians who used different methods to get correlations they wanted. After Pearson helped make correlations more rigorous, the problem flipped to people over-attributing meaning to correlations they generated. In other words, 100 years ago people put in correlations that didn’t belong, now they fail to take them out.
Okay, that’s it for this week! We’ll see you back here next week for Statistical traps and trickery.
Week 5 is up! Read it here.





 Issue: Visually, this chart shows the tax rate will quadruple or quintuple if the Bush tax cuts aren’t extended. If the axis started at zero however, the first bar would be about 90% the size of the second one.
Issue: Visually, this chart shows the tax rate will quadruple or quintuple if the Bush tax cuts aren’t extended. If the axis started at zero however, the first bar would be about 90% the size of the second one.




