Back in February I did a post called Women, Ovulation and Voting in 2016, about various researchers attempts to prove or disprove a link between menstrual cycles and their voting preferences. As part of that critique, I had brought up a point that Andrew Gelman made about the inherently dubious nature of anyone claiming to find a 20+ point swing in voting preference. People just don’t tend to vary their party preference that much over anything, so they claim on it’s face is suspect.
I was thinking of that this week when I saw a link to this HBR article from back in April that sort of gender-flips the ovulation study. In this research (done in March), they asked men whether they would vote for Trump or Clinton if the election were today. For half of the men they first asked them a question about how much their wives made in comparison to them. For the other half, they got that question after they’d stated their political preference. The question was intended to be a “gender prime” to get men thinking about gender and present a threat to their sense of masculinity. Their results showed that men who had to think about gender roles prior to answering political preference showed a 24 point shift in voting patterns. The “unprimed” men (who were asked about income after they were asked about political preference) had preferred Clinton by 16 points, and the “primed” men preferred Trump by 8 points. If the question was changed to Sanders vs Trump, the priming didn’t change the gap at all. For women, being “gender primed” actually increased support for Clinton and decreased support for Trump.
Now given my stated skepticism of 20+ point swing claims, I decided to check out what happened here. The full results of the poll are here, and when I took a look at the data there was one thing that really jumped out at me: a large percent of the increased support for Trump came from people switching from “undecided/refuse to answer/don’t know” to “Trump”. Check it out, and keep in mind the margin of error is +/-3.9:
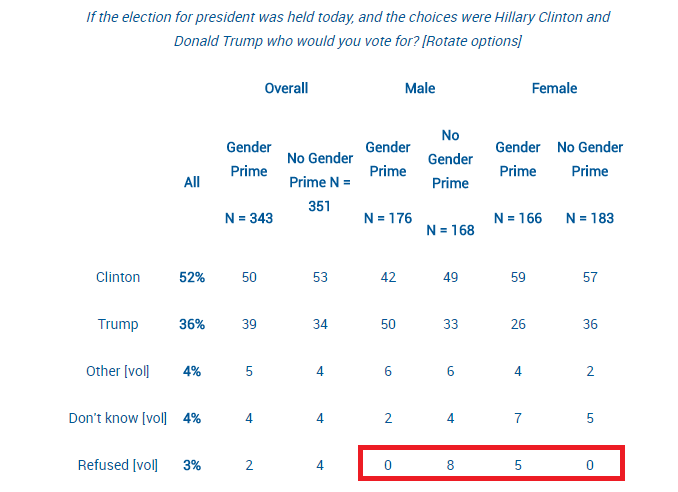
So basically men who were primed were more likely to give an answer (and that answer was Trump) and women who were primed were less like to answer at all. For the Sanders vs Trump numbers, that held true for men as well:

In both cases there was about a 10% swing in men who wouldn’t answer the question when they were asked candidate preference first, but would answer the question if they were “primed” first. Given the margin of error was +/-3.9 overall, this swing seems to be the critical factor to focus on…..yet it was not mentioned in the original article. One could argue that hearing about gender roles made men get more opinionated, but isn’t it also plausible the order of the questions caused a subtle selection bias? We don’t know how many men hung up on the pollster after being asked about their income with respect to their wives, or if that question incentivized other men to stay on the line. It’s interesting to note that men who were asked about their income first were more likely to say they outearned their wives, and less likely to say they earned “about the same” as them…..which I think at least suggests a bit of selection bias.
As I’ve discussed previously, selection bias can be a big a big deal…and political polls are particularly susceptible to it. I mentioned Andrew Gelman previously, and he had a great article this week about his research on “systemic non-response” in political polling. He took a look at overall polling swings, and used various methods to see if he could differentiate between changes in candidate perception and changes in who picked up the phone. His data suggests that about 66-85% of polling swings are actually due to a change in the number of Republicans and Democrats who are willing to answer pollsters questions as opposed to a real change in perception. This includes widely reported on phenomena such as “post convention bounce” or “post debate effects”. This doesn’t mean the effects studied in these polls (or the studies I covered above) don’t exist at all, but that they may be an order of magnitude more subtle than suggested.
So whether you’re talking about ovulation or threats to male ego, I think it’s important to remember that who answers is just as important as what they answer. In this case 692 people were being used to represent the 5.27 million New Jersey voters, so any the potential for bias is, well, gonna be yuuuuuuuuuuuuuuuuuuge.
