Note: This is part 8 in a series for high school students about reading and interpreting science on the internet. Read the intro and get the index here or go back to Part 7 here.
I love this part of the talk because I get to present my absolute favorite study of all time. Up until now I’ve mostly been covering things about how other people are trying to fool you to get them to your side, but now I’m going to wade in to how we seek to fool ourselves. That’s why I’m calling this part:
Biased Interpretations and Motivated Reasoning
Okay, so what’s the problem here?
The problem here my friend, is you. And me. Well, all of us really…..especially if you’re smart. The unfortunate truth is that for all the brain power we put towards things, our application of that brain power can vary tremendously when we’re evaluating information that we like, that we’re neutral towards, or that we don’t like. How tremendously? Well, in 2013 the working paper “Motivated Numeracy and Enlightened Self-Government“, some researchers decided to ask if people with a rash got better if they used a new skin cream. They provided this data:
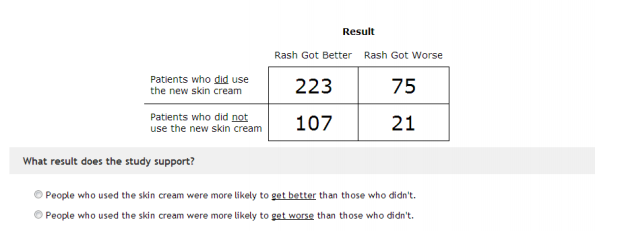
The trick here is that you are comparing absolute value to proportion. More people got better in the “use the skin cream” group, but more people also got worse. The proportion is better for those who did not use the cream (about 5:1) as opposed to those who did use it (about 3:1). This is a classic math skills problem, because you have to really think through what question you’re trying to answer before you calculate, and what you are actually comparing. Baseline about 40% of people in the study got this right.
What the researchers did next was really cool. For some participants, they took the original problem, kept the numbers the same, but changed “patients” to “cities”, “skin cream” to “strict gun control laws” and “rash” to “crime”. They also flipped the outcome around for both problems, so participants had one of four possible questions. In one the skin cream worked, in one it didn’t, in one strict gun control worked, in one it didn’t. The numbers in the matrix remained the same, but the words around them flipped. They also asked people their political party and a bunch of other math questions to get a sense of their overall mathematical ability. Here’s how people did when they were assessing rashes and skin cream:
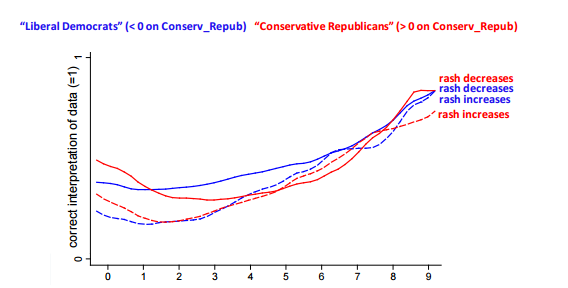
Pretty much what we’d expect. Regardless of political party, and regardless of the outcome of the question, people with better math skills did better1.
Now check out what happens when people were shown the same numbers but believed they were working out a problem about the effectiveness of gun control legislation:
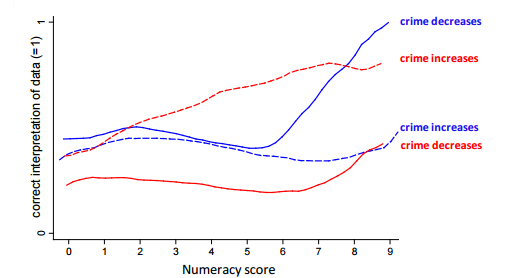
Look at the end of that graph there, where we see the people with a high mathematical ability. If using their brain power got them an answer that they liked politically, the did it. However, when the answer didn’t fit what they liked politically, they were no better than those with very little skill at getting the right answer. Your intellectual capacity does NOT make you less likely to make an error….it simply makes you more likely to be a hypocrite about your errors. Yikes.
Okay, so what kind of things should we be looking out for?
Well, this sort of thing is most common on debates where strong ethical or moral stances intersect with science or statistics. You’ll frequently see people discussing various issues, then letting out a sigh and saying “I don’t know why other people won’t just do their research!”. The problem is that if you believe something strongly already, you’re quite likely to think any research that agrees with you is more compelling than it actually is. On the other hand, research that disagrees with you will look less compelling than it may be.
This isn’t just a problem for the hoi polloi either. I just wrote earlier this week about two research groups who were accusing the other of choosing statistical methods that would support their own pet conclusions. We all do it, we just see it more clearly when it’s those we disagree with.
Why do we fall for this stuff?
Oh so many reasons. In fact Carol Tarvis has written an excellent book about this (Mistakes Were Made (but Not by Me): Why We Justify Foolish Beliefs, Bad Decisions, and Hurtful Acts) that should be required reading for everyone. In most cases though it’s pretty simple: we like to believe that all of our beliefs are perfectly well reasoned and that all the facts back us up. When something challenges that assumption, we get defensive and stop thinking clearly. There’s also some evidence that the internet may be making this worse by giving us access to other people who will support our beliefs and stop us from reconsidering our stances when challenged.
In fact, researchers have found that the stronger your stance towards something, the more likely you are to hold simplistic beliefs about it (ie “there are only two types of people, those who agree with me and those who don’t”).
An amusing irony: the paper I cited in that last paragraph was widely reported on because it showed evidence that liberals are as bad about this as conservatives. That may not surprise most of you, but in the overwhelmingly liberal field of social psychology this finding was pretty unusual. Apparently when your field is >95% liberal, you mostly find that bias, dogmatism and simplistic thinking are conservative problems. Probably just a coincidence.
So what can we do about it?
Richard Feynman said it best:

If you want to see this in action, watch your enemy. If you want to really make a difference, watch yourself.
Well that got heavy. See you next week for Part 9!
1. You’ll note this is not entirely true at the lowest end. My guess is if you drop below a certain level of mathematical ability, guessing is your best bet.↩