Welcome to the Calling Bullshit Read-Along based on the course of the same name from Carl Bergstorm and Jevin West at the University of Washington. Each week we’ll be talking about the readings and topics they laid out in their syllabus. If you missed my intro and want the full series index, click here or if you want to go back to Week 10 click here.
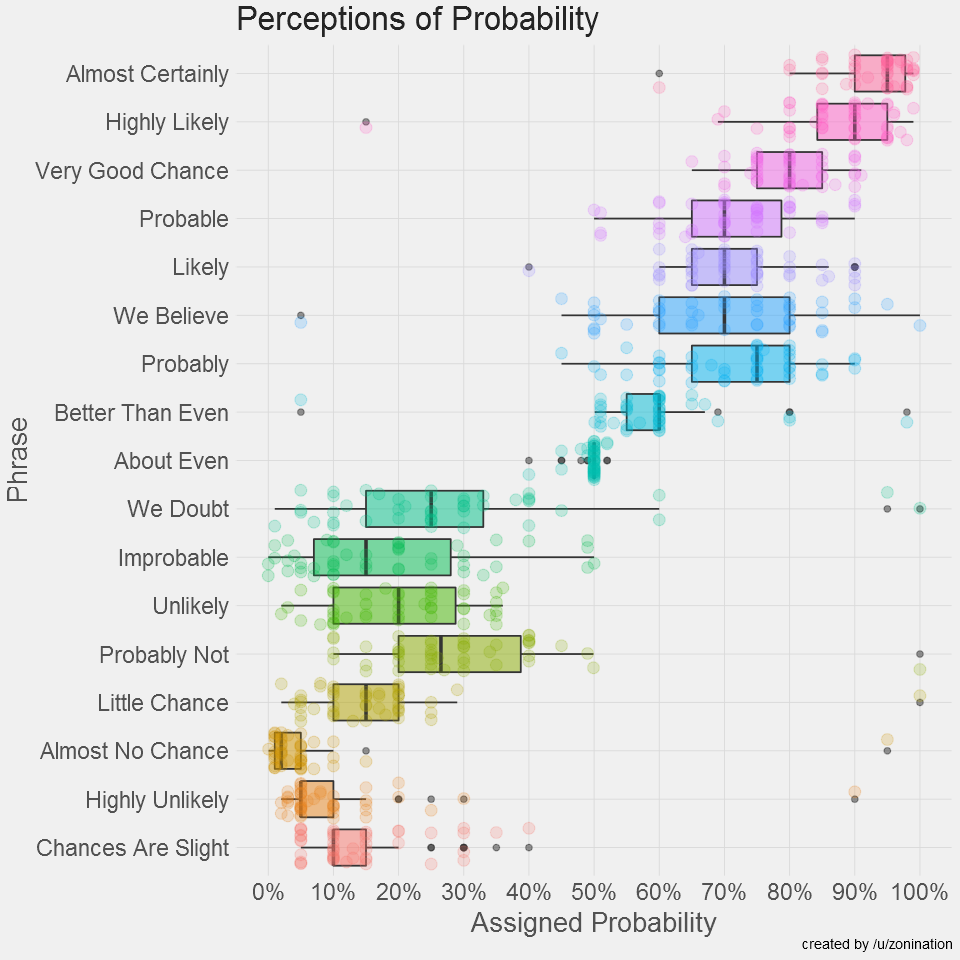
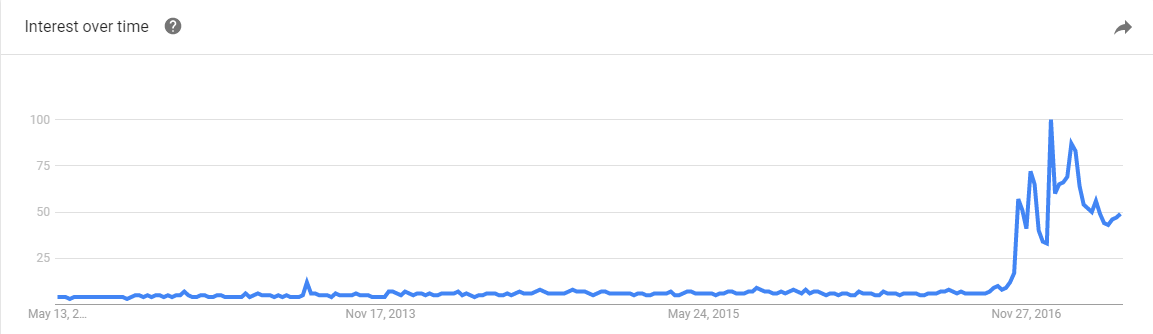
Guys, guys, it’s week 11! We’re down to our second to last read-along, and this week we’re tackling the topic that has recently skyrocketed in popularity public awareness: fake news. To give you a sense of how new this term is to public discussion, check out the Google trends history:

Now Google trends isn’t always the best way of figuring out how popular a search term is (the x-axis is a comparison of the term to its own peak of popularity) but it does let us know the interest in this term really took off after the US election in November and has not settled back down. Apparently when online fake news started prompting real life threats of nuclear war, people took notice.
But what is fake news exactly, and is it really a new phenomena? That’s the question our first reading sets out to answer. The article “Before Fake News Came False Prophecy” uses some British history to frame our current debate, and makes the assertion that “prophecy” about ones political opponents was the old time version of fake news. I hadn’t previously connected the idea of prophecy to the idea of fake news, but it really is the historic equivalent: guarantees that dark and terrible things will happen (or may already be happening) if your enemies are allowed to be (or remain) in charge. As the article says “Prophecy didn’t describe the world as it was, but as it was to be—or as it might become. That fantasy was more powerful than any lived reality. People killed and died for fantasies. People didn’t act politically because of what they had lost but because of what, in their most potent fantasy, they feared losing.”
With that framing, fake news becomes not just a tool of misinformation, but actually something that’s playing off our imagination. It blurs the line between “this is true because it happened” and “this is true because it might happen”.
Okay, so fake news is bad, but what is it really? The next reading from Factcheck.org actually takes that on a bit before they go in to the ever important “how to spot it” topic. They quote the guy who started Snopes and point out that “fake news” or fake stories made up by websites trying to make money is really a subset of “bad news” which is (as he puts it) “shoddy, unresearched, error-filled, and deliberately misleading reporting that does a disservice to everyone”. I think the “this is just one branch of a tree of bad” point is an important point to keep in mind, and I’ll circle back to it later. That being said, there is something a little bit different about entirely fictitious stories, and there are some red flags you should look for. Factcheck gives a list of these, such as anonymous authors, lots of exclamation points, links to sources that don’t support the story, and quoting “Fappy the Anti-Masturbation Dolphin” as a source. They also caution that you should always check the date on stories, as sometimes people attempt to connect true older stories to current events as though they were more recent. They also highlight people who don’t realize known satirists are satire (see the website Literally Unbelievable for a collection of people who don’t know about the Onion).
So why are we so worried about fake news? Can’t we just ignore it and debunk as needed? Well….maybe, but some of this is a little more organized than you may think. The next reading “The Agency” is a long but chilling New York Times investigation in to, some real world accounts of some rather scary fake news moments. They start with a bizarre case of a reported but non-existent chemical plant explosion in Louisiana. This story didn’t just get reported to the media but was texted to people who lived nearby the plant, posted on Twitter with doctored local Louisiana news reports and the whole thing started trending on Twitter and getting picked up nationally while the actual chemical plant employees were still pulling themselves out of bed and trying to figure out what was going on. While no one really identified a motivation for that attack, the NYTs found links to suggest it was orchestrated by a group from Russia that employs 400 people to do nothing but spread fake news. This group works 12 hour days trolling the internet causing chaos in comments sections on various sites all over the place for purposes that aren’t clear to almost anyone, but with an end result of lots of aggravation for everyone.
Indeed, this appears to be part of the point. Chen’s investigation suggests that after the internet was used to mobilize protests in Russia few years ago, the government decided to hit back. If you could totally bog down political websites and comments sections with angry dreck, normal people wouldn’t go there. At best, you’d convince someone that the angry pro-government opinions were the majority and that they should play along. Failing that, you’d cut off a place where people might have otherwise gathered to express their discontent. Chen tracks the moves of the Russian group in to US events, which ultimately ends up including a campaign against him. The story of how they turned him from a New York Times reporter in to a neo-Nazi CIA recruiter is actually so bizarre and incredible I cannot do it justice, so go read the article.
Not every fake news story is coming out of a coordinated effort however, as yet another New York Times article discusses. Some of it is just from regular people who discovered that this is a really good way of making money. Apparently bullshit is a fairly lucrative business.
Slight tangent: After the election, a close family member of mine was reading an article on the “fake news” topic, and discovered he had actually gone to college with one of the people interviewed. The guy had created a Facebook group we had heard of that spewed fake and inflammatory political memes and was now making (allegedly) a six figure monthly salary to do so. The guy in question was also fairly insane (like “committed assault over a minor dorm dispute” type insane), and had actually expressed no interest in politics during college. In real life, he had trouble making friends or influencing people, but on the internet he turned his knack for conflict and pissing people off in to a hefty profit. Now I know this is just a friend of a friend story and you have now real reason to believe me, but I think the fundamental premise of “these news stories/memes might have creators who you wouldn’t let spend more than 5 minutes in your living room” is probably a good thing to keep in mind.
So why do people share these things? Well, as the next reading goes in to, the answer is really social signaling. When you share a news story that fits your worldview, you proclaim allegiance to your in-group. When you share a fake news story, you also probably enrage your out-group. By showing your in-group that you are so dedicated to your cause that you’re willing to sacrifice your reputation with your out-group, you increase your ties with them. The deeper motivations here are why simply introducing contradictory facts doesn’t always work (though they sometimes do – more on the most recent research on the “backfire effect” here), particularly if you get snarky about it. People may not see it as a factual debate, but rather a debate about their identity. Yikes. The article also mentions three things you can personally do to help 1) Correct normal errors, but don’t publicly respond to social signalling. 2) Make “people who value truth” your in-group and hold yourself to high standards 3) Leave room for satire, including satire of your own beliefs.
I endorse this list.
Finally, we take a look at how technology is adding to the problem, not just by making this stuff easier to share, but sometimes by promoting it. In the reading “Google’s Dangerous Identity Crisis“, we take a look at Google’s “featured” search results. These are supposed to be used to highlight basic information like “what time does the Superbowl start” but can also end up highlighting things like “Obama is planning a coup”. The identity crisis in question is whether Google exists simply to index sites on the web or whether it is verifying some of those sites as more accurate than others. The current highlighting feature certainly looks like an endorsement of a fact, but it’s really just an advanced algorithm that can be fooled pretty easily. What Google can or should be doing about that is up for debate.
Whew, okay, that was a lot of fake news, and a lot of depressing stuff. What would I add to this whole mess? Well, I really liked the list given in the CNN article. Not boosting people’s signalling, watching your own adherence to truth and keeping a sense of humor are all good things. They other thing I’ve found very effective is to try to have more discussions about politics with people I know and trust. I think online news stories (fake or not) are frequently like junk food: easy to consume and easy to overdo it with. Even discussions with friends who don’t agree with me can never match the quick hit vitriolic rush of 100 Twitter hot takes.
The second thing I’d encourage is to not let the “fake news” phenomena distract from the “bad news” issues that can be perpetuated by even respectable news sources. The FactCheck article quoted the guy from Snopes.com on this topic, and I think it’s important. Since the rise of the “fake news” phenomena, I’ve had a few people tell me that fact checking traditional media is no longer as important. That seems horribly off to me. Condemning fake news should be part of a broader movement to bring more accuracy to all of our news.
Okay, that’s all I’ve got for today. Check back in next week for the last class!