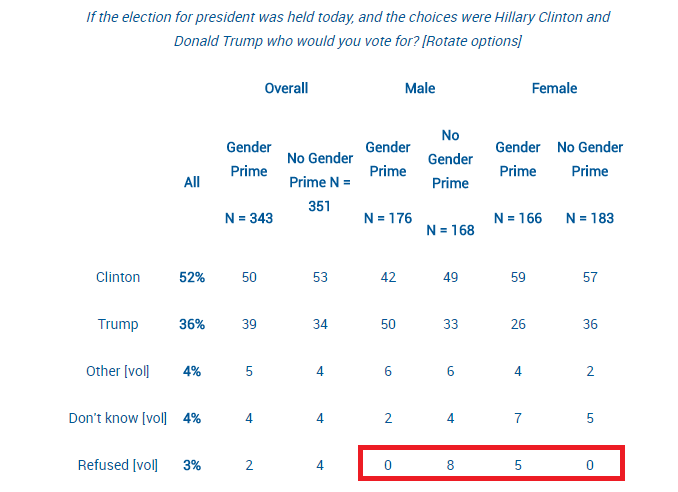
Last week, commenter Christopher B left an interesting comment on my post about masculinity threats and voting that made me realize I wanted to do a bigger post on priming studies in general. Priming studies have come under a lot of fire in the past few years, and they have the unfortunate distinction of being called (by some) the “poster child for doubts about the integrity of psychological research“. So what’s going on here? What are these studies and why do they go wrong so often?
Well, as Christopher B pointed out, it’s not because priming isn’t a thing. Priming is typically defined as “an implicit memory effect in which exposure to one stimulus (i.e., perceptual pattern) influences the response to another stimulus“. In other words, something you see or do at one point unconsciously biases you to act differently at a later date. Some of these could be pretty straightforward. If you see a list of words that containing the word “dog” and then someone asks you to name an animal that starts with the letter w, you will probably be more likely to say “wolf” than “walrus”. Lots of marketers attempt to use priming-like effects to get people to buy more or differently than they would have otherwise. There’s even some efforts to see if getting alcoholics to physically (well, in the form of video games) practice pushing away drinks helps lead to lower rates of relapse. I think most of us would accept that your brain does have a bit of an auto-suggest type system, and most people would accept it can probably be manipulated subtly. So where’s the problem? Well, in addition to the p-value and replication issues I’ve raised before, here’s some other reasons things have gone haywire:
- A lot of work gets done at the edges The examples I’ve given above are pretty straightforward, much more straightforward than most of the priming studies that get attention. It’s unsurprising that most researchers aren’t as interested in obvious and straightforward effects, but rather increasingly subtle and indirect effects. For example, in the study I talked about last week, the researchers didn’t ask men to consider a world where women reigned supreme, but rather asked “who makes more money, you or your wife?” The effects they’re interested in are subtle and subconscious, and obviously there’s a limit to how far that can be stretched. Finding that limit is part of the goal. Unfortunately, the edges of any phenomena are going to be those most susceptible to signal and noise problems, and priming researchers got in the habit of casting a broad net at the edges of their conceptual field. Let’s just say that if your field ends up lending itself to parody this pointed, you may want to take a step back.
- Primes themselves are subject to bias There’s a great paper on priming studies out of Stanford called “Why many priming results don’t (and won’t) replicate: A quantitative analysis” that points out a lot of logistical reasons priming studies don’t work. One of the more interesting issues they raise is that it’s really freaking hard to actually establish how strong a prime is, and the choices are made by things that are obvious to the researcher, not necessarily the subjects. For example, the most famous priming study primed undergrads with words associated with the elderly like “Florida” or “sentimental”. The authors of the quantitative analysis paper pointed out that the frequency of those words being associated with “elderly people” has actually been decreasing in the past several decades. So basically things that will be “obvious” associations to a 40 year old researcher may not be as obvious to their 18 year old students. To give a more run of the mill example of this, think of celebrity names. If I ask you to name an actor whose first name is “Alan”, many baby boomers might say “Alda”, whereas younger Harry Potter fans may say “Rickman”. This issue also explains why these studies don’t tend to replicate in other languages.
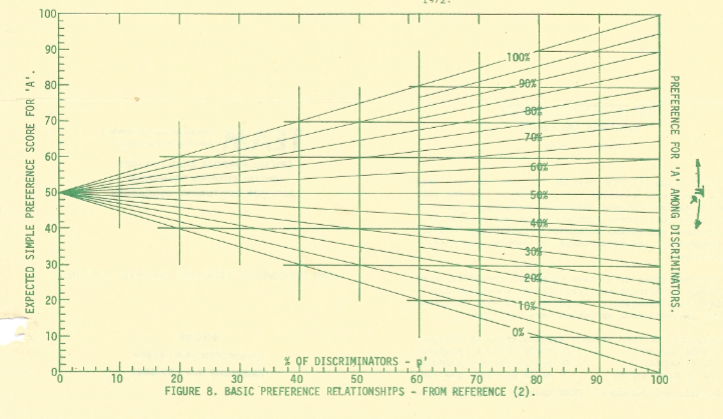
- Age of subjects matters In addition to the word choice bias, there’s some good evidence that our susceptibility to priming may actually change as we age. When attempts have been made to actually create new word association relationships for people, age is a confounder:
 Image from the quantitative analysis paper. The authors in that paper propose that this will translate in to young people being much more susceptible to subtle primes, with older people only responding to more direct ones. This age discrepant behavior is not always accounted for.
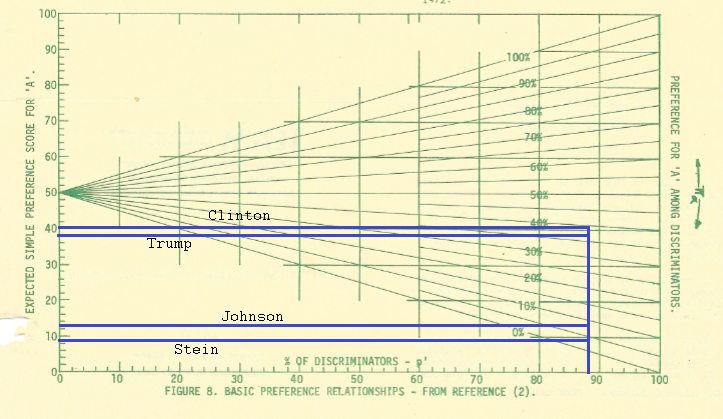
Image from the quantitative analysis paper. The authors in that paper propose that this will translate in to young people being much more susceptible to subtle primes, with older people only responding to more direct ones. This age discrepant behavior is not always accounted for. - Experimenters can prime just as well as their actual primes One of the main blows to priming studies came when a group of researchers attempted to replicate the “hear words about old people/subsequently walk more slowly” study. In a study called “Behavioral Priming: It’s All in the Mind, but Whose Mind?”, researchers found that priming the researcher to believe the subjects had been primed to walk more slowly caused the participants to walk more slowly. In fact the researcher’s belief made a bigger difference than the priming itself:
Turns out subjects aren’t the only ones susceptible to subtle and unconscious biases. You can read the original studies author rather grouchy response to the whole thing here, and Andrew Gelman’s eyeroll back here.
- The field did attract an unfortunate number of frauds. Maybe it was due to the headline grabbing nature of many of these priming studies, but there have been some absolutely audacious fraud cases in priming research. Diederik Staples published over 20 big studies with made up data. Dirk Smeesters also had seven. Lawrence Sanna is up to 8. Is this worse than other fields? Maybe, or maybe it’s just that these studies tended get a lot of attention. It’s not so much the fraud that casts a shadow, but the alarming realization that so many made up studies got through without question. This has led to calls for standards involving immediate replication attempts and other measures to stop bad research before it starts.

Now keep in mind, all of these reasons are over and above the normal file drawer effect and p-hacking that all fields face. Hopefully this gives you a little insight in to a few of the less obvious ways these studies can go wrong, and will trigger you to think about these things when you hear the word “prime”….see what I did there????