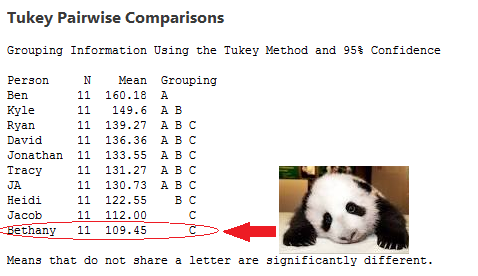
One of the very first lessons every statistics students learns in class is how to use measures of central tendency to assess data. While in theory this means most people should have at least a passing familiarity with the terms “average” or “mean, median and mode”, the reality is often quite different. For whatever reason, when presented with a statement about your average we seem to forget the profound vulnerabilities of the “average”. Here’s some of the most common:
- Leaving a relevant confounder out of your calculations Okay, so maybe we can never get rid of all the confounders we should, but that doesn’t mean we can’t try at least a little. The most commonly quoted statistic I hear that leaves out relevant confounders is the “Women make 77 cents for every dollar a man earns” claim. Now this is a true statement IF you are comparing all men in the US to all women in the US, but it gets more complicated if you want to compare male/female pay by hours worked or within occupations. Of course “occupation and hours worked” are two things most people actually tend to assume are included in the original statistic, but they are not. The whole calculation can get really tricky (Politifact has a good breakdown here), but I have heard MANY people tag “for the exact same work” on to that sentence without missing a beat. Again, it’s not possible to control for every confounder, but your first thought when you hear a comparison of averages should be to make sure your assumptions about the conditions are accurate.
- A subset of the population could be influencing the value of the whole population. Most people are at least somewhat familiar with the idea of outlier type values and “if Bill Gates walks in to a bar, the average income goes way up” type issues. What we less often consider is how different groups being included/excluded from a calculation can influence things. For example, in the US we are legally required to educate all children through high school. The US often does not do well when it comes to international testing results. However in this review by the Economic Policy Institute, they note that in some of the countries (Germany and Poland for example) certain students are assigned to a “vocational track” quite early and may not end up getting tested at all. Since those children likely got put on that track because they weren’t good test takers, the average scores go up simply by removing the lowest performers. We saw a similar phenomena within the US when more kids started taking the SATs. While previous generations bemoaned the lower SAT scores of “kids these days” the truth was those were being influenced by expanding the pool of test takers to include a broader range of students. Is that the whole explanation? Maybe not, but it’s worth keeping in mind.
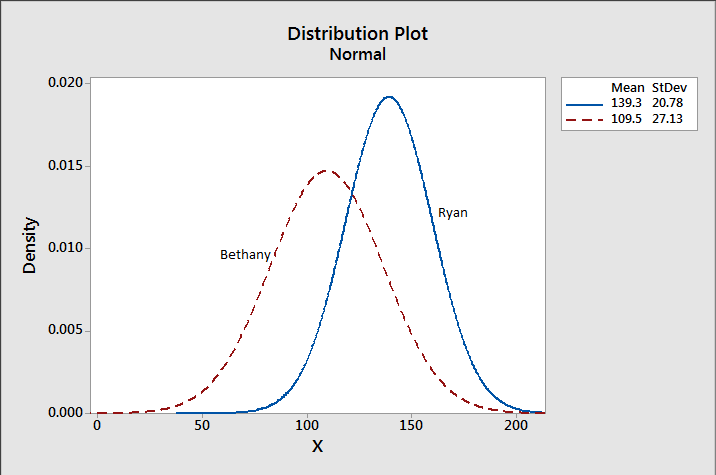
- The values could be bimodal (or another non-standard distribution) One of my first survey consulting gigs consisted of taking a look at some conference attendee survey data to try and figure out what the most popular sessions/speakers were. One of the conference organizers asked me if he could just get a list of the sessions with the highest average ranking. That sounded reasonable, but I wasn’t sure that was what they really wanted. You see, this organization actually kind of prided itself on challenging people and could be a little controversial. I was fairly sure that they’d feel very differently about a session that had been ranked mostly 1’s and 10’s, as opposed to a session that had gotten all 5’s and 6’s. To distill the data to a simple average would be to lose a tremendous amount of information about the actual distribution of the ratings. It’s like asking how tall the average human is…..you get some information, but lose a lot in the process. Neither the mean or median account for this.
- The standard deviations could be different Look, I get why people don’t always report on standard deviations….the phrase itself probably causes you to lose at least 10% of readers automatically. However, just because two data sets have the same average doesn’t mean the members of those groups look the same. In #3 I was referring to those groups that have two distinct peaks on either side of the average, but even less dramatic spreads can cause the reality to look very different than the average suggests.
- It could be statistically significant but not practically significant. This one comes up all the time when people report research findings. You find that one group does “more” of something than another. Group A is happier than Group B. When you read these, it’s important to remember that given a sample size large enough ANY difference can become statistically significant. A good hint this may be an issue is when people don’t tell you the effect size up front. For example, in this widely reported study it was shown that men with attractive wives are more satisfied with their marriages in the first 4 years. The study absolutely found a correlation between attractiveness of the wife and the husband’s marital satisfaction….a gain of .36 in satisfaction (out of a possible 45 points) for every 1 point increase in attractiveness (on a scale of 1 to 10). That’s an interesting academic finding, but probably not something you want to knock yourself out worrying about.
Beware the average.