Those of you who follow any sort of science/data/skepticism news on Twitter will have almost certainly have heard of the new pre-print taking the internet by storm this week: “Supercentenarians and the oldest-old are concentrated into regions with no birth certificates and short lifespans“.
This paper is making a splash for two reasons:
- It is taking on a hypothesis that has turned in to a cottage industry over the years.
- The statistical reasoning makes so much sense it makes you feel a little silly for not questioning point #1 earlier.
Of course #2 may be projection on my part, because I have definitely read the whole “Blue Zone” hypothesis (and one of the associated books) and never questioned the underlying data. So let’s go over what happened here, shall we?
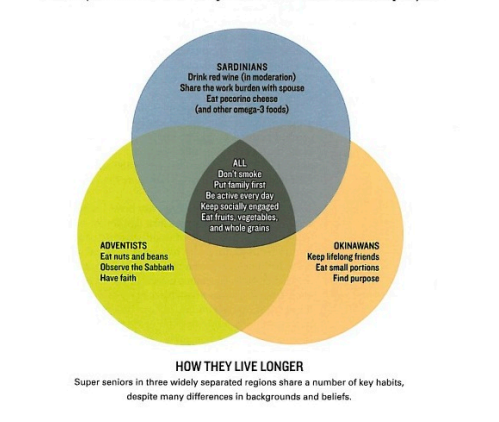
For those of you not familiar with the whole “Blue Zone” concept, let’s start there. The Blue Zones were something popularized by Dan Buettner who wrote a long article about them for National Geographic magazine back in 2005. The article highlighted several regions in the world that seemed to have extraordinary longevity: Sardinia (Italy), Okinawa (Japan) and Loma Linda (California, USA). All of these areas seemed to have a very above average number of people living to be 100. They studied their habits to see if they could find anything the rest of us could learn. In the original article, that was this:

This concept proved so incredibly popular that Dan Buettner was able to write a book, then follow up books, then a whole company around the concept. Eventually Ikaria (Greece) and Nicoya Peninsula (Costa Rica) were added to the list.
As you can see the ultimate advice list obtained from these regions looks pretty good on its face. The idea that not smoking, making good family and social connections, daily activity and fruits and vegetables are good certainly isn’t turning conventional wisdom on it’s head. So what’s being questioned?
Basically the authors of the paper didn’t feel that alternative explanations for longevity had been adequately tested, specifically the hypothesis that maybe not all of these people were as old as they said they were or that otherwise bad record keeping was inflating the numbers. While many of the countries didn’t have clean data sets, they were able to pull some data sets from the US, and discovered that the chances of having people in your district live until they were 110 fell dramatically once state wide birth registration was introduced:

Now this graph is pretty interesting, and I’m not entirely sure what to make of it. There seems to be a peak at around -15 years before implementation, which is interesting, with some notable fall off before birth registration is even introduced. One suspects birth registration might be some proxy for expanding records/increased awareness of birth year. Actually, now that I think about it, I bet we’re catching some WWI and WWII related things in here. I’m guessing the fall off before complete birth registration had something to do with the draft around those wars, where proving your age would have been very important. The paper notes that the years 1880 to 1900 have the most supercentenarians born in those years, and there was a draft in 1917 for men 21-30. Would be interesting to see if there’s a cluster of men at birth years just prior to 1887. Additionally the WWII draft start in 1941 went up to 45, so I wonder if there’s a cluster at 1897 or just before. Conversely, family lore says my grandfather exaggerated his age to join the service early in WWII, so it’s possible there are clusters at the young end too.
The other interesting thing about this graph is that it focused on supercentenarians, aka those who live to 110 or beyond. I’d be curious to seem the same data for centenarians (those who live to 100) to see if it’s as dramatic. A quick Google suggests that being a supercenetarian is really rare (300ish in the US out of 320 million) but 72,000 or so centenarians. Those living to 90 or over number well over a million. It’s much easier to overwhelm very rare event data with noise than more frequent data. I have the Blue Zone book on Kindle, so I did a quick search and noticed that he mentioned “supercenterians” 5 times, all on the same page. Centenarians are mentioned 167 times.
This is relevant because if we saw a drop off in all advanced ages when birth registrations were introduced, we’d know that this was potentially fraudulent. However, if we see that only the rarest ages were impacted, then we start to get in to issues like typos or other very rare events as opposed to systematic misrepresentation. Given the splash this paper has made already, I suspect someone will do that study soon. Additionally, the only US based “Blue Zone”, Loma Linda California, does not appear to have been studied specifically at all. That also may be worth looking at to see if the pattern still holds.
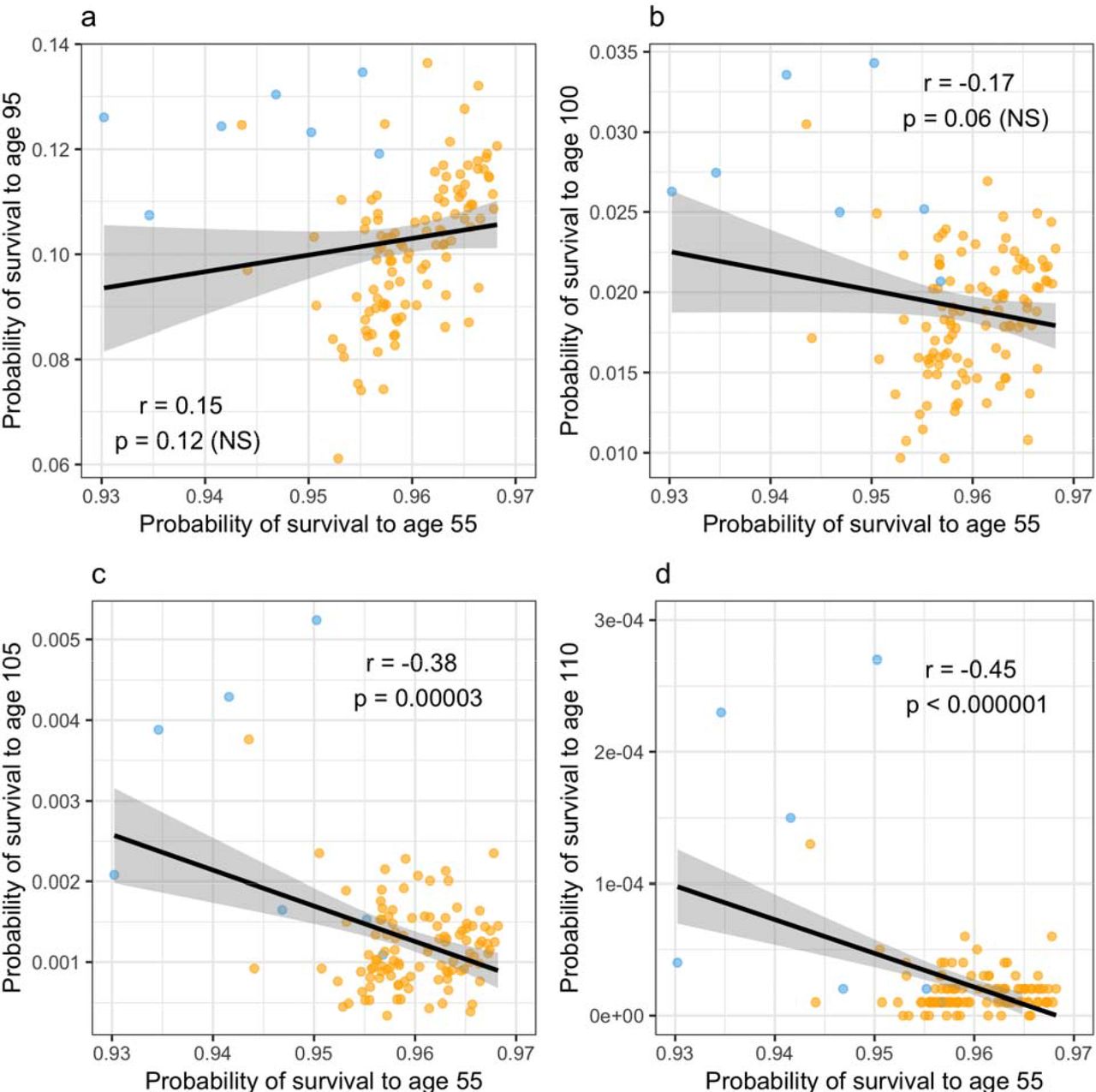
The next item the paper took a shot at was the non-US locations, specifically Okinawa and Sardinia. From my reading I had always thought those areas were known for being healthy and long lived, but the paper claims they are actually some of the poorest areas with the shortest life expectancies in their countries. This was a surprise to me as I had never seen this mentioned before. But here’s their data from Sardinia:

The Sardinian provinces are in blue, and you’ll note that there is eventually a negative correlation between “chance of living to 55” and “chance of living to 110”. Strange. In the last graph in particular there seem to be 3 provinces in particular that are causing the correlation to go negative, and one wonders what’s going on there. Considering Sardinia as a whole has a population of 1.6 million, it would only take a few errors to produce that rate of longevity.
On the other hand, I was a little surprised to see the author cite Sardinia as having on of the lowest life expectancies. Exact quote “Italians over the age of 100 are concentrated into the poorest, most remote and shortest-lived provinces,”. In looking for a citation for this, I found on Wiki this report (in Italian). It had this table:

If I’m using Google translate correctly, Sardegna is Sardinia and this is a life expectancy table from 2014. While it doesn’t show Sardinia having the highest life expectancy, it doesn’t show it having the lowest either. I tried pulling the Japanese reports, but unfortunately the one that it looks the most useful is in Japanese. As noted though, the paper hasn’t yet gone through peer review, so it’s possible some of this will be clarified.
Finally, I was a little surprised to see the author say “[these] patterns are difficult to explain through biology, but are readily explained as economic drivers of pension fraud and reporting error.” While I completely agree about errors, I do actually think there’s a plausible mechanism that would cause poor people who didn’t live to 55 as often to have longer lifespans. Deaths under 55 tend to be from things like accidents, suicide, homicide and congenital anomalies….external forces. The CDC lists the leading causes of death by age group here: 
Over 55, we mostly switch to heart disease and cancer. A white collar office worker with a high stress job and bad eating habits may be more likely to live to 55 than a shepherd who could get trampled, but once they’re both 75 the shepherd may get the upper hand.
I’m not doubting the overall hypothesis by the way….I do think fraud or errors in record keeping can definitely introduce issues in to the data. Checking outliers to make sure they aren’t errors is key, and having some skepticism about source data is always warranted. After writing most of this post though, I decided to check back in on the Blue Zones book to see if they addressed this. To my surprise, the book claims that at least in Sardinia, this was actually done. On page 25 and 26, they mention specifically how much doubt they faced and how one doctor personally examined about 200 people to help establish their truthfulness about their age. Dr Michel Poulain (a Belgian demographer) apparently was nominated by a professional society specifically to go to Sardinia to check for signs of fraud. According to the book, he visited the region ten times to review records and interview people. I have no idea how thorough he was or how his methods hold up, but his work seems at odds with the idea that someone just blindly pulled ages out of a database or the papers claim that “These results may reflect a neglect of error processes as a potential generative factor in remarkable age records”. Interestingly, I’d imagine WWI and WWII actually help with much of the work here. Since I’d imagine most people have very vivid memories of where they were and what they were doing during the war years, those stories might go far to establishing age.
Basically, it seems like sporadic exaggeration, error or fraud might give mistaken impressions about how many supercenteranian people there are overall, but I do wonder if having an unusual cluster brings enough scrutiny that we don’t have to worry as much that something was missed. In the Blue Zone book, they mention the group that brought attention to the Sardinians had helped debunk 3 other similar claims. Also, as mentioned, the paper doesn’t mention if the one US blue zone was one of the ones to get late birth registration, but I do know the Seventh Day Adventists are one of the most intensely studied groups in the country.
Anyway, given the attention and research that has been paid to these areas, I’d imagine we’re going to hear some responses soon. Dr Poulain appears to still be active, and one suspects he will be responding to this questioning of his work. This post is getting my “things to check back in on” tag. Stay tuned!