Ah, at last we come to the end. This chapter is about the knowns, the known unknowns and the unknown unknowns. While that’s a somewhat hard to follow sentence, it does make for a nice contingency matrix, and is really the crux of the Black Swan argument. Here’s my take:
One of the most dangerous mistakes you can make is to confuse unfamiliar and improbable. What you don’t know CAN hurt you.
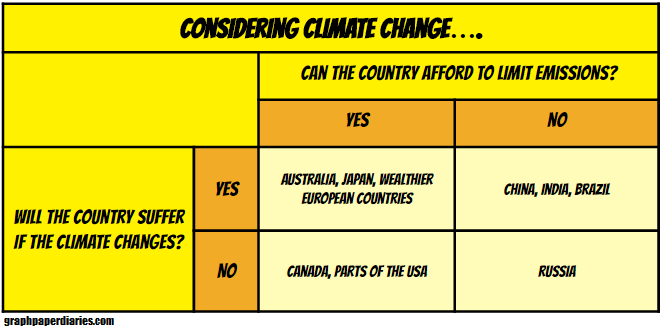
This chapter had some great stuff about climate change and models of climate change. One of the more interesting parts (to me) was the review of the motivations of various countries when it comes to climate change treaties. Not every country arrives at the table on the same page, no matter what their leaders believe:
Chapter 11 has a lot on bubbles and why they develop. Interestingly, Silver actually uses the whole “two ways to be wrong” thing directly, in order to point out that a trader who loses money in one way (selling only to have the market go up) is much more likely to be penalized than a trader who loses money with everyone else (buying only to have the market crash). This is why traders are so hesitant to acknowledge a bubble….they know that going against the crowd will get them far more penalized than making the same mistake as everyone else. Explains a lot, if you think about it.
Chapter 10 was about poker, and how to make money playing poker. Apparently the key is to make it easy for lots of inexperienced people to play. When websites that made it easy to play got shut down, fewer inexperienced people made the effort and many previously “successful” players discovered they were now the fish. It’s a good reminder to keep an eye on the skill level of your competition in addition to your own.
Chapter 9 has some interesting anecdotes about the quest to create a chess program that could beat Gary Kasparov. It covers some of the limits of humans and machines, and how they are almost better when used in tandem.
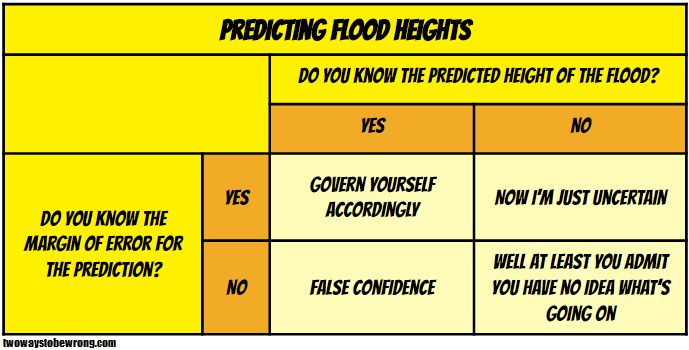
I’ve been going through the book The Signal and the Noise, and pulling out some of the anecdotes in to contingency matrices. Chapter 6 covers margin of error and communicating uncertainty.
There’s a great anecdote in the opening of this chapter about flood heights and margin of error. If your levee is only built to contain 51 feet of water, then you REALLY need to know that the weather service prediction is 49 feet +/- 9, not just 49 feet.
This is bad enough, but Silver also points out that we almost never get a margin of error or uncertainty for economic predictions. This is probably why they’re all terrible, especially if they come from a politically affiliated group.
The lesson here is knowing what you don’t know is sometimes more important than knowing what you do know.
Apparently we’re terrible at predicting earthquakes.
That’s what Chapter 5 is about, and it makes sense. Predicting rare events (Black Swans as Taleb would call them) is terribly difficult because you may only be working with a theoretical possibility and a limited data set. Even though we can get a general sense of where earthquakes may hit, we still don’t get much data on the major ones. This map from Wired shows some interesting regional information:
So with limited data points, the tendency for predictions is going to be to take every data point seriously and risk overfitting the model. The other problem is not going far enough back with the data. In Japan prior to the Fukashima disaster, evidence that major earthquakes had hit thousands of years ago was left off the risk assessment.
My most memorable earthquake experience was actually a few weeks after my son was born. I was feeding him, and I thought a large truck had gone by. Something felt off though, and he seemed surprisingly confused by it. When I went downstairs again, I checked the news and realized that “truck” had been an earthquake.
I’ve been going through the book The Signal and the Noise, and pulling out some of the anecdotes in to contingency matrices. Chapter 4 covers weather forecasts.
Chapter 4 of this book was pretty interesting, as it covered weather predictions from various sources. It presented some data that showed how accurate weather predictions from various sources were. Essentially the graphs plotted the prediction (i.e. “20% chance of rain”) against the frequency of rain actually occurring after the prediction. They found that the National Weather Service is the most accurate, then the Weather Channel, then local TV stations.
While that was interesting in and of itself, what really intrigued me was the discussion of whether an accurate forecast was actually a good forecast. People watching the local news for their weather are almost invariably going to make decisions based on that forecast, so meteorologists actually have a lot of incentives to exaggerate bad weather a bit. After all, people are much less likely to be annoyed by the time they brought an umbrella and didn’t need it than the time they got soaked by a storm they didn’t expect. The National Weather Service on the other hand is taxpayer funded to be as accurate as possible, and may end up seeing their track record put in front of Congress at some point. Different incentives mean different choices.
To give you an idea of the comparison, when the National Weather Service says the chance of rain is 100%, it’s about 98%. When the Weather Channel says it, it’s about 92%. When a local station says it, it’s about 68%. When Aaron Justus says it….well, this happens: