A reader going by the name of “Sound Information” sent along the following graph from this Brietbart article, with this comment:
Just saw the following graph in a Breitbart article, and thought “wow! those increasing bar lengths really indicate increase” — except really they are just an artifact of earlier dates being closer to the y-axis than later ones.
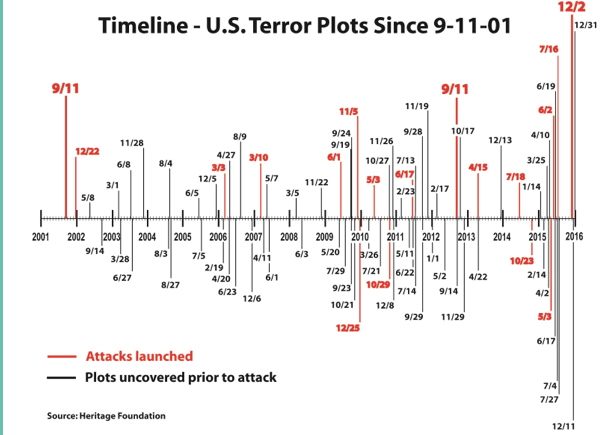
It’s a good point. The bar lengths do, at first glance, appear to represent something in terms of magnitude. It’s only when you look closely that you realize their length is mostly about making the dates readable. I was curious how this graph would look if I just took the absolute numbers for each year so I did that and I came up with this graph:

Note: all I did was transcribe their data. They got it from this Heritage Foundation timeline, and I didn’t look to see what got counted or not. I did however, take a look at discrepancies. I think I found 2 typos and 1 intentional addition to the Brietbart data:
- Breitbart lists a plot on June 3, 2008 that the Heritage Foundation doesn’t list and I couldn’t find (probably typo).
- The Heritage Foundation has a plot listed on May 16, 2013 that Brietbart did not include (probably typo).
- September 11th, 2012 is included on the Breitbart list but not the Heritage Foundation one. This is the date of the Benghazi attacks on the US embassy in Libya (almost certainly intentionally added)
So overall there does appear to be an increase in absolute number, at least of the plots and events we know about or have record of. This is one of those strange areas where we never quite know how big the sample size was. Some plots (especially single person events) likely fizzle with no one knowing, and more massive plots might be kept from us by FBI/CIA/etc for ongoing investigation reasons.
The other thing missing from both graphs of course is the magnitude of any of these attacks. 2015 had 15 plots or attacks overall, but 9 of those involved just one person, and 5 involved 2 people. It’s hard to know if it’s more accurate to show number of events, magnitude of events or both. It feels strange to look at 9/11/01 and say “that’s one”, but there also is some value in seeing trends of smaller events.
Regardless of how you do the numbers, I think we all hope 2016 is a record low in every way possible.