Last week, the Assistant Village Idiot forwarded me a new paper called “A cleansing fire: Moral outrage alleviates guilt and buffers threats to one’s moral identity“. It’s behind a ($40) paywall, but Reason magazine has an interesting breakdown of the study here, and the AVI does his take here. I had a few thoughts about how to think about a study like this, especially if you don’t have access to the paper.
So first, what did the researchers look at and what did they find? Using Mechanical Turk, the researchers had subject read articles that talked about either labor exploitation in other countries or the effects of climate change. They found that personal feelings of guilt about those topics predicted greater outrage at a third-party target, a greater desire to punish that target, and that getting a chance to express that outrage decreased guilt and increased feelings of personal morality. The conclusion being reported is (as the Reason.com headline says) “Moral outrage is self-serving” and “Perpetually raging about the world’s injustices? You’re probably overcompensating.”
.
So that’s what’s being reported. So how do we think through this when we can’t see the paper? Here’s 5 things I’d recommend:
- Know what you don’t know about sample sizes and effect sizes Neither the abstract nor the write ups I’ve seen mention how large the effects reported were or how many people participated. Since it was a Mechanical Turk study I am assuming the sample size was reasonable, but the effect size is still unknown. This means we don’t know if it’s one of those unreasonably large effect sizes that should alarm you a bit or one of those small effect sizes that is statically but not practically significant. Given that reported effect size heavily influences the false report probability, this is relevant.
- Remember the replication possibilities Even if you think a study found something quite plausible, it’s important to remember that fewer than half of psychological studies end up replicating exactly as the first paper reported. There are lots of possibilities for replication, and even if the paper does replicate it may end up with lots of caveats that didn’t show up in the first paper.
- Tweak a few words and see if your feelings change Particularly when it comes to political beliefs, it’s important to remember that context matters. This particular studies calls to mind liberal issues, but do we think it applies to conservative issues too? Everyone has something that gets them upset, and it’s interesting to think through how that would apply to what matters to us. When the Reason.com commenters read the study article, some of them quickly pointed out that of course their own personal moral outrage was self serving. Free speech advocates have always been forthright that they don’t defend pornographers and offensive people because they like those people, but because they want to preserve free speech rights for themselves and others. Self serving moral outrage isn’t so bad when you put it that way.
- Assume the findings will get more generic In addition to the word tweaks in point #3, it’s likely that subsequent replications will tone down the findings. As I covered in my Women Ovulation and Voting post, 3 studies took findings from “women change their vote and values based on their menstrual cycle” to “women may exhibit some variation in face preference based on menstrual cycle”. This happened because some parts of the initial study failed to replicate, and some caveats got added. Every study that’s done will draw another line around the conclusions and narrow their scope.
- Remember the limitations you’re not seeing One of the most important parts of any papers is where the authors discuss the limitations of their own work. When you can’t read the paper, you can’t see what they thought their own limitations where. Additionally, it’s hard to tell if there were any interesting non-findings that didn’t get reported. The limitations that exist from the get go give a useful indication of what might come up in the future.
So in other words….practice reasonable skepticism. Saves time, and the fee to read the paper.
 If you think about it, this makes a lot of sense. If money is a struggle, it affects your happiness. Once you’ve stopped struggling, it stops having the same effect. So basically it’s more accurate to say that money can’t buy happiness, but a lack of money sure can stress you out.
If you think about it, this makes a lot of sense. If money is a struggle, it affects your happiness. Once you’ve stopped struggling, it stops having the same effect. So basically it’s more accurate to say that money can’t buy happiness, but a lack of money sure can stress you out.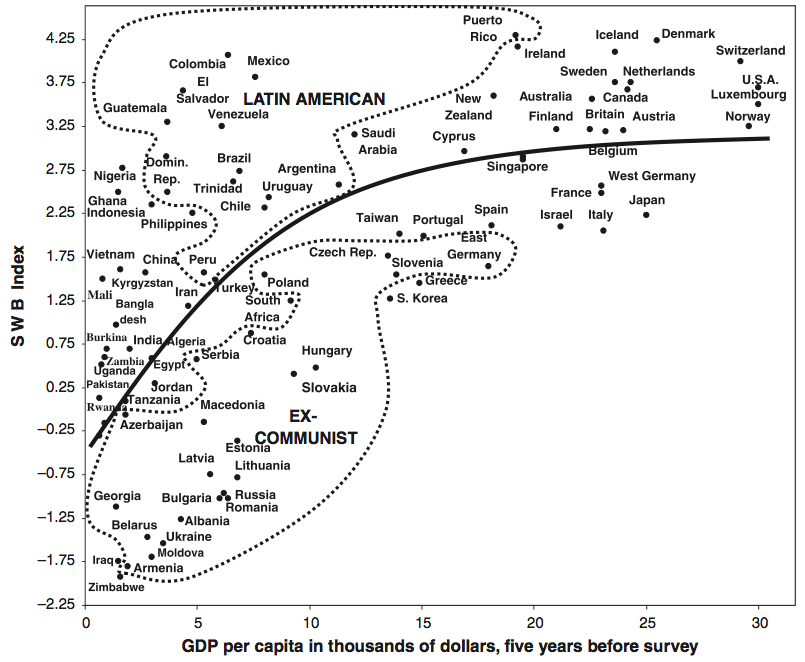 So countries that struggle to develop do take their toll on their citizens, but at some point development stops yielding returns in well being. It would be interesting to see if the effect of personal wealth varied with country GDP, but alas I can’t find that data.
So countries that struggle to develop do take their toll on their citizens, but at some point development stops yielding returns in well being. It would be interesting to see if the effect of personal wealth varied with country GDP, but alas I can’t find that data.


{kind=link}