I got an interesting question from the Assistant Village Idiot recently, pointing me to this blog post1 on materialism and post-materialism in various countries by year, wealth of nation, wealth of individual, age and education level of respondent. It’s an interesting compilation of graphs and research that seem to show us, as a world, moving from a materialistic mindset, to a post-materialistic mindset. So what does that mean and what’s my take?
First, some definitions.
Up front the definitions are given as follows:
Materialist: mostly concerned with material needs and physical and economic security
Post-materialist: strive for self-actualization, stress the aesthetic and the intellectual, and cherish belonging and esteem
What interested me is that if you go all the way to the end, you find that the question used to categorize people was actually a little more specific. They asked people the following question:
“If you had to choose among the following things, which are the two that seem most desirable to you?”
- Maintaining order in the nation. (Materialist)
- Giving the people more say in important political decisions. (Post-materialist)
- Fighting rising prices. (Materialist)
- Protecting freedom of speech. (Post-materialist)
People then receive a score between 1 and 3. If you pick both materialist options (#1 and #3), you get a score of 1. If you pick both post-materialist options (#2 and #4), you get a score 3. If you pick one of each, you get a score of 2.
So what are we seeing?
Well, this (from this paper here):
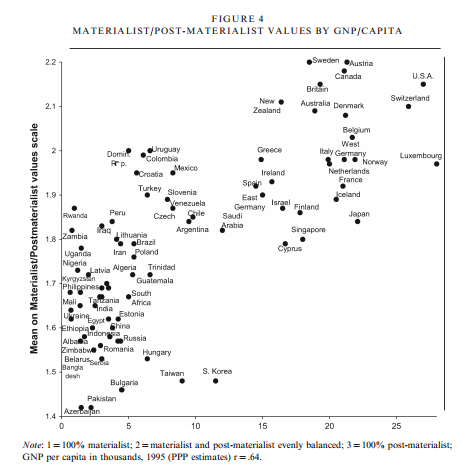
Every country in the world scores (on average) between a 1.4 and a 2.2. There were also graphs that showed that higher class people moved toward post-materialist mindset, and that the world as a whole has been moving towards it over the years.
I do think it’s worth noting that only about 8 countries score over a 2, with a few more on the line. On the whole, more countries skew materialist than post-materialist on this scale…..though the 8 that are higher are all fairly high on the development index.
So what does this mean?
Well, it seems to be a matter of focus. In my opinion, these questions seem to serve as a proxy for current concerns as much as actual preferences. For example, I did not rank “fighting rising prices” very high, but I also live in a country that has only slow inflation for most of my life. Essentially, this appears to be a sort of political Maslow’s hierarchy of needs. It’s most likely not that people don’t care about safety or price stability, but rather they don’t prioritize it if they already have it. Additionally, I would suspect that many people would argue that they like free speech because it maintains order in a country, as opposed to actually desiring free speech over order.
Most of the data comes from one particular researcher, Ronald Inglehart, who focuses on changing values and theorizing what impact that might have on society. Inglehart is not particularly hypothesizing that being post-materialist is bad, but rather that it represents a departure from the way most people have lived for thousands of years. Because it appears our values slant is set earlier in life, he proposes that those of us growing up in relative safety and security will always bias towards a post-materialist focus. He researches what effect that may have on society.
While some of this may seem obvious, he brings up a couple related outcomes that were fairly subtle. For instance, he points out in this paper that we have seen a reduction in voting stratified by social class, and an increase in voting stratified around social issues. This suggests that even a very basic level of security like the type provided by our welfare systems allows people more time to focus on their values and ideals. It varied by country, but in the US there was almost NO difference in materialist/post-materialist values by education class.
This was an interesting point, because I think many people are troubled by how contentious some of our social issue debates have gotten (abortion, women’s rights, the environmental movement, etc) have all gotten. The idea that these issues are now more contentious because more people are devoting more thought to them is intriguing. Additionally, it seems that there would be less national agreement on those types of issues in comparison to safety and security issues. If your country is under attack, there is no debate about defending yourself. We may debate the method, but the outcome is widely agreed upon. With social issues that’s not true. What effect this will have on country level stability is unknown.
Interesting stuff to keep an eye on going forward, and keep in mind this election season.
1. Max Roser (2016) – ‘Materialism and Post-Materialism’. Published online at OurWorldInData.org. Retrieved from: https://ourworldindata.org/materialism-and-post-materialism/ [Online Resource]↩







