Welcome to “So Why ARE Most Published Research Findings False?”, a step by step walk through of the John Ioannidis paper “Why Most Published Research Findings Are False”. It probably makes more sense if you read this in order, so check out the intro here , Part 1 here and Part 2 here.
Okay, first a quick recap: Up until now, Ioannidis has spent most of the paper providing a statistical justification for considering not just study power and p values, but also made a case for including pre-study odds, bias measures, and the number of teams working on a problem as items to look at when trying to figure out if a published finding is true or not. Because he was writing a scientific paper and not a blog post, he did a lot less editorializing than I did when I was breaking down what he did. In this section he changes all that, and he goes through a point by point breakdown of what this all means with a set of 7 6 corollaries. The words here in bold are his, but I’ve simplified the explanations. Some of this is a repeat from the previous posts, but hey, it’s worth repeating.
Corollary 1: The smaller the studies conducted in a scientific field, the less likely the research findings are to be true. In part 1 and part 2, we saw a lot of graphs that showed good study power had a huge effect on result reliability. Larger sample sizes = better study power.
Corollary 2: The smaller the effect sizes in a scientific field, the less likely the research findings are to be true. This is partially just intuitive, but also part of the calculation for study power. Larger effect sizes = better study power. Interestingly, Ioannidis points out here that given all the math involved, any field looking for effect sizes smaller than 5% is pretty much never going to be able to confirm their results.
Corollary 3: The greater the number and the lesser the selection of tested relationships in a scientific field, the less likely the research findings are to be true. That R value we talked about in part 1 is behind this one. Pre-study odds matter, and fields that are generating new hypotheses or exploring new relationships are always going to have more false positives than studies that replicate others or meta-analyses.
Corollary 4: The greater the flexibility in designs, definitions, outcomes, and analytical modes in a scientific field, the less likely the research findings are to be true. This should be intuitive, but it’s often forgotten. I work in oncology, and we tend to use a pretty clear cut end point for many of our studies: death. Our standards around this are so strict that if you die in a car crash less than 100 days after your transplant, you get counted in our mortality statistics. Other fields have more wiggle room. If you are looking for mortality OR quality of life OR reduced cost OR patient satisfaction, you’ve quadrupled your chance of a false positive.
Corollary 5: The greater the financial and other interests and prejudices in a scientific field, the less likely the research findings are to be true. This one’s pretty obvious. Worth noting: he points out “trying to get tenure” and “trying to preserve ones previous findings” are both sources of potential bias.
Corollary 6: The hotter a scientific field (with more scientific teams involved), the less likely the research findings are to be true. This was part of our discussion last week. Essentially it’s saying that if you have 10 people with tickets to a raffle, the chances that one of you wins is higher than the chances that you personally win. If we assume 5% of positive findings happen due to chance, having multiple teams work on a question will inevitably lead to more false positives.
Both before and after listing these 6 things out, Ioannidis reminds us that none of these factors are independent or isolated. He gives some specific examples from genomics research, but then also gives this helpful table. To refresh your memory, the 1-beta column is study power (influenced by sample size and effect size), R is the pre-study odds (varies by field), u is bias, and the “PPV” column over on the side there is the chance that a paper with a positive finding is actually true. Oh, and “RCT” is “Randomized Control Trial”:
I feel a table of this sort should hang over the desk of every researcher and/or science enthusiast.
Now all this is a little bleak, but we’re still not entirely at the bottom. We’ll get to that next week.
Part 4 is up! Click here to read it.
 If you think about it, this makes a lot of sense. If money is a struggle, it affects your happiness. Once you’ve stopped struggling, it stops having the same effect. So basically it’s more accurate to say that money can’t buy happiness, but a lack of money sure can stress you out.
If you think about it, this makes a lot of sense. If money is a struggle, it affects your happiness. Once you’ve stopped struggling, it stops having the same effect. So basically it’s more accurate to say that money can’t buy happiness, but a lack of money sure can stress you out.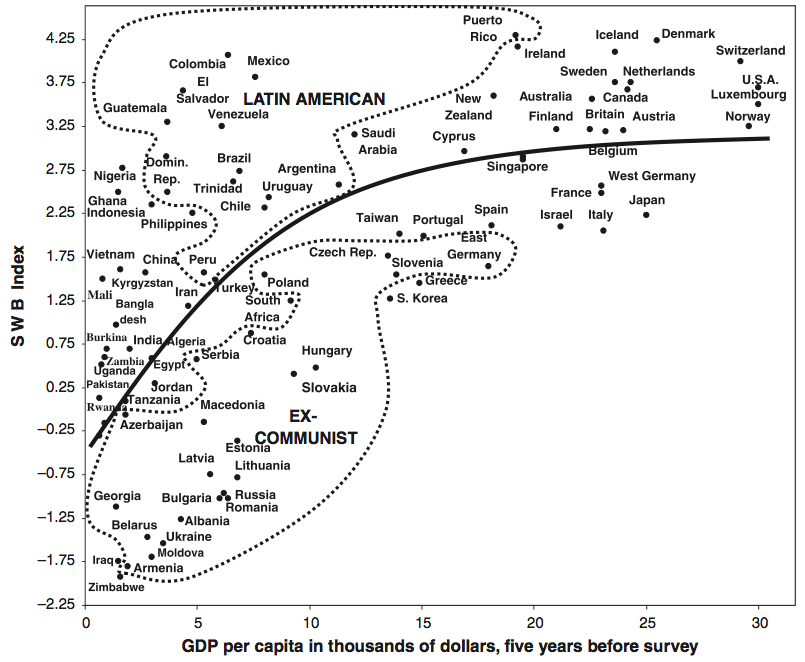 So countries that struggle to develop do take their toll on their citizens, but at some point development stops yielding returns in well being. It would be interesting to see if the effect of personal wealth varied with country GDP, but alas I can’t find that data.
So countries that struggle to develop do take their toll on their citizens, but at some point development stops yielding returns in well being. It would be interesting to see if the effect of personal wealth varied with country GDP, but alas I can’t find that data.





{kind=link}
{kind=link}