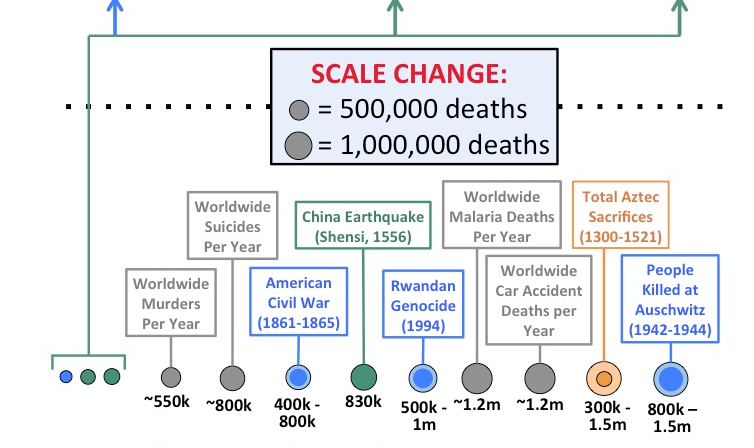
Okay, after discussing Type I and Type II errors a few weeks ago and Type III errors last week, it’s only natural that this week we’d move on to Type IV errors. This is another error type that doesn’t have a formal definition, but is important to remember because it’s actually been kind of a problem in some studies. Basically, a Type IV error is an incorrect interpretation of a correct result.
For example, let’s say you go to the doctor because you think you tore your ACL
A Type I error would occur if the doctor told you that your ACL was torn when it wasn’t. (False Positive)
A Type II error would occur if the doctor told you that you just bruised it, but you had really torn your ACL. (False Negative)
A Type III error would be if the doctor said you didn’t tear your ACL, and you hadn’t, but she sent you home missed that you had a tumor on your hip causing the knee pain. (Wrong problem)
A Type IV error would be if you were correctly diagnosed with an ACL tear, then told to put crystals on it every day until it healed. Alternatively, the doctor refers for surgery and the surgery makes the problem worse. (Wrong follow up)
When you put it like that, it’s decently easy to spot, but a tremendous number of studies can end up with some form of this problem. Several papers have found that when using ANOVA tables, as many as 70% of authors will end up doing incorrect or irrelevant follow up statistical testing. Sometimes these affect the primary conclusion and sometimes not, but it should be concerning to anyone that this could happen.
Other types of Type IV errors:
- Drawing a conclusion for an overly broad group because you got results for a small group. This is the often heard “WEIRD” complaint, when psychological studies use populations from White Educated Industrialized Rich Democratic countries (especially college students!) and then claim that the results are true of humans in general. The results may be perfectly accurate for the group being studied, but not generalizable.
- Running the wrong test or running the test on the wrong data. A recent example was the retraction that had to be made when it turned out the authors of a paper linking conservativism and psychotic traits had switched the coding for conservatives and liberals. This meant all of their conclusions were exactly reversed, and they now linked liberalism and psychotic traits. They correctly rejected the null hypothesis, but were still wrong about the conclusion.
- Pre-existing beliefs and confirmation bias. There’s interesting data out there that suggests that people who write down their justifications for decisions are more hesitant to walk back on those decisions when it looks like they are wrong. It’s hard for people to walk back on things once they’ve said them. This was the issue with a recent Politifact “Pants on Fire Ranking” ranking it gave a Donald Trump claim. Trump had claimed that “crime was rising”. PolitiFact said he was lying. When it was pointed out to them that preliminary 2015 and 2016 data suggests that violent crime is rising, they said preliminary data doesn’t count stood by the ranking. The Volokh Conspiracy has the whole breakdown here, but it struck them (and me) that it’s hard to call someone a full blown liar if they have preliminary data on their side. It’s not that his claim is clearly true, but there’s a credible suggestion it may not be false either. Someone remind me to check when those numbers finalize.
In conclusion: even when you’re right, you can still be wrong.